
Dans le paysage commercial actuel, qui évolue rapidement, les entreprises de toutes tailles sont confrontées à un afflux massif de données. Celles-ci comprennent un large éventail de données non structurées, c’est-à-dire des données qui ne sont pas organisées proprement dans un format de base de données structuré traditionnel. Parmi les exemples de données non structurées, on peut citer les courriels, les textes, les images, les vidéos, etc.
Des études récentes suggèrent que jusqu’à 80 % de ces nouvelles données ne sont pas structurées, ce qui pose des problèmes importants aux entreprises pour les capturer, les quantifier, les traiter et les archiver de manière efficace. La capacité à extraire les informations essentielles de ces données et à les transformer en données exploitables déterminera si les entreprises peuvent acquérir un avantage concurrentiel. C’est là que le parsing de fichiers entre en jeu. Mais de quoi s’agit-il au juste ?
Dans ce blog, nous allons expliquer ce qu’est le parsing de fichiers, les technologies qui le sous-tendent, comment les entreprises peuvent l’exploiter et comment Klippa peut vous aider à automatiser le parsing de fichiers.
Êtes-vous prêt ? Commençons !
Qu’est-ce que le parsing de fichiers ?
Le parsing de fichiers est une technique utilisée par les entreprises pour extraire des informations essentielles de données non structurées. Elle consiste à analyser le contenu des fichiers, tels que les documents textuels ou les images, afin d’en extraire les points de données pertinents et de les transformer en un format utilisable.

Le parsing de fichiers est souvent utilisé par les entreprises dans le traitement des données pour transformer des données non structurées telles que des fichiers PDF en formats prêts à l’emploi tels que CSV, XML, JSON, XLMS, et bien d’autres. Un parsing de fichiers efficace et précis joue un rôle important dans de nombreux secteurs et domaines où l’afflux de données est important et où le traitement des données est une tâche critique.
Comment les entreprises peuvent-elles parser les informations contenues dans les fichiers ? Nous couvrirons cette question par la suite.
Comment parser des fichiers ?
Supposons que votre entreprise reçoive des fichiers PDF et que vous deviez en extraire les informations utiles pour les stocker dans votre base de données ou les saisir dans votre système informatique. Normalement, ce travail serait effectué par des employés du back-office qui liraient le fichier PDF et copieraient manuellement les informations dans le système informatique.
Avec un parseur de fichier, vous pouvez parser (lire) le fichier PDF, extraire les informations nécessaires et les exporter, par exemple sous forme de fichier JSON, en l’espace de quelques secondes. Ce fichier peut ensuite être envoyé et traité dans votre système informatique, sans intervention humaine.
Ce sont là quelques exemples courants d’entreprises qui utilisent le parsing de fichiers pour extraire des données ou convertir les données d’un format non structuré à un format structuré:
- Conversion d’images en texte pour réduire la saisie manuelle de données
- Exporter des données de fichiers PDF vers JSON, CSV, XML et de nombreux autres formats
- Le parsing des e-mails pour en extraire des informations significatives
- Extraction de paires clé-valeur à partir de documents tels que des factures et des reçus
- Extraction de données pertinentes à partir de documents d’identité pour l’accueil des clients
Bien entendu, il existe de nombreux autres exemples où le parsing de fichiers peut être utilisé pour obtenir les informations extraites de documents non structurés. Maintenant que vous savez où l’analyse syntaxique de fichiers peut être utilisée, examinons ses composants les plus essentiels:
- OCR
- Machine Learning (en français “Apprentissage automatique”)
- Langage de programmation
OCR
La reconnaissance optique de caractères (OCR) est la technologie la plus essentielle dans le parsing de fichiers car elle permet d’extraire des informations à partir d’images ou de documents scannés. Les analyseurs de fichiers utilisent la technologie OCR pour convertir les images en texte lisible par les machines. Ce texte converti est ensuite traité, analysé et transformé en données structurées en vue d’une utilisation ultérieure.
Imaginez que vous deviez traiter de nombreuses factures scannées et saisir manuellement toutes les informations pertinentes dans un système ERP ou comptable. Cette opération peut prendre beaucoup de temps et être sujette à des erreurs. L’OCR permet d’éliminer ce travail manuel en extrayant le texte des documents numérisés.
Cependant, l’OCR peut extraire plus d’informations que ce qui est nécessaire d’un point de vue commercial. C’est là que les parseurs de fichiers font la différence, car ils peuvent lire et interpréter les données, en produisant un format de fichier structuré qui ne contient que les résultats significatifs pour une utilisation ultérieure.
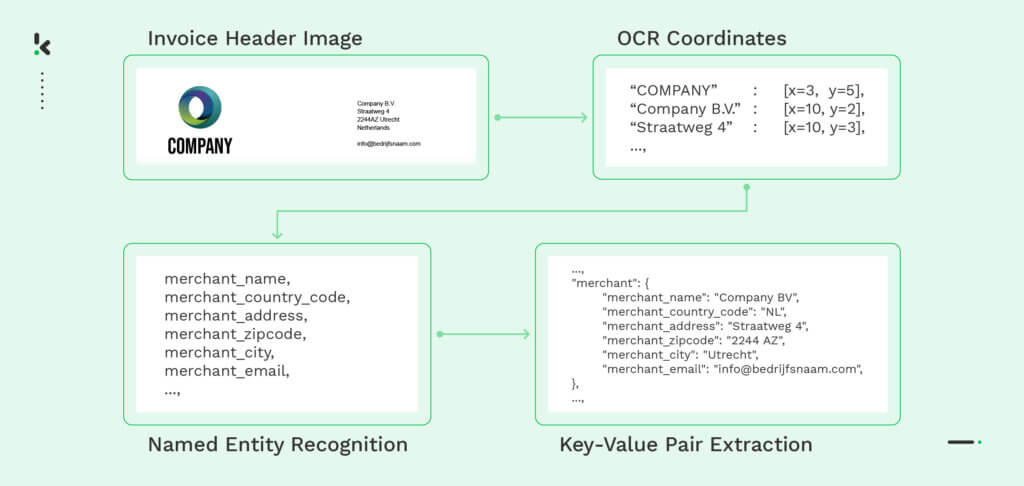
L’exemple suivant montre comment un parseur de fichiers basé sur l’OCR extrait des informations à partir de l’image d’une facture. Dans un premier temps, la facture est numérisée à l’aide de l’OCR, puis les champs de données nécessaires, tels que le nom et l’adresse du commerçant, sont identifiés à l’aide de Named Entity Recognition – NER (en français la reconnaissance d’entités nommées). Enfin, le moteur d’analyse extrait les informations en paires clé-valeur qui peuvent être converties dans un format lisible par une machine, tel que JSON. Ce processus permet une extraction efficace et précise des données à partir de différents formats de fichiers.
Machine Learning
Les algorithmes basés sur machine learning, qui est un sous-ensemble de l’intelligence artificielle (IA), sont utilisés pour améliorer les capacités des parseurs de fichiers de diverses manières. Par exemple, les algorithmes machine learning peuvent être entraînés à reconnaître des informations ou des modèles spécifiques à partir de documents pour l’extraction de données.
Les parseurs de fichiers sans machine learning peuvent avoir du mal à extraire des données précises dans des cas complexes. Dans ce cas, des algorithmes de vérification orthographique, de validation ou de nettoyage des données peuvent être utilisés pour identifier et corriger les erreurs dans les données parsées, telles que les fautes d’orthographe, les valeurs manquantes ou les formats de données incohérents. L’intégration de machine learning dans les parsers améliore la précision et les performances des opérations d’extraction de données et d’analyse syntaxique de fichiers.
Les langues de programmation
Il existe plusieurs langages de programmation qui fournissent des bibliothèques et des fonctions intégrées ou tierces permettant aux développeurs de construire des parseurs pour extraire et transformer les informations stockées dans des fichiers ayant des formats ou des structures de données spécifiques.
Voici quelques langages de programmation populaires pour les parseurs de fichiers:
- Python
- Java
- Javascript
- Golang
- Ruby
Python est un langage de programmation polyvalent connu pour sa simplicité et sa lisibilité. Il dispose d’un riche écosystème de bibliothèques, telles que les parseur de fichiers CSV, JSON, XML et binaires, qui facilitent parse et la manipulation de fichiers de différents formats.
Java un langage de programmation populaire, est connu pour son indépendance vis-à-vis des plates-formes et sa prise en charge solide de la programmation orientée objet. Il offre une large gamme de bibliothèques qui fournissent des capacités étendues de parsing de fichiers ; Apache POI pour les fichiers Microsoft Office, Jackson pour les fichiers JSON, et JAXB pour les fichiers XML. Ces bibliothèques font de Java un choix polyvalent pour les tâches de parsing de fichiers.
JavaScript est un langage de script populaire principalement utilisé pour le développement web. Il possède des capacités de parsing JSON intégrées, ainsi que des bibliothèques étendues qui permettent des fonctionnalités de parsing de fichiers ; PapaParse pour le parsing CSV et xml2js pour le parsing XML.
Go également connu sous le nom de Golang, est un langage de programmation statiquement typé et compilé développé par Google. Go dispose de bibliothèques standard qui offrent de solides capacités de parsing de fichiers : encoding/csv pour le parsing CSV, encoding/json pour le parsing JSON, et encoding/xml pour le parsing XML.
Ruby est un langage de programmation dynamique orienté objet, connu pour sa syntaxe élégante et sa facilité d’utilisation. Il dispose d’un support intégré pour le parsing de fichiers texte, ainsi que de bibliothèques : CSV pour le parsing CSV, Nokogiri pour le parsing XML et HTML, et JSON pour le parsing JSON.
Il s’agit là de quelques illustrations des nombreux langages de programmation qui peuvent être utilisés pour créer des parseurs de fichiers. Comme vous l’avez peut-être déjà compris, le choix d’un langage de programmation dépend des besoins spécifiques du format de fichier analysé, des considérations de performance et de la familiarité avec le langage.
Néanmoins, la grande polyvalence de Python en fait un langage de programmation très populaire dans le domaine de parsing de fichiers. Dans les sections suivantes, nous verrons plus en détail comment Python est utilisé pour parser des données à partir de fichiers.
Parser en Python
Comme nous l’avons déjà mentionné, Python est l’un des choix les plus populaires en tant que langage de programmation pour l’analyse de fichiers. Cela n’est pas seulement dû à sa polyvalence, mais aussi à sa facilité d’utilisation et à la grande disponibilité des bibliothèques et des modules. Grâce à ses solides capacités de manipulation de chaînes de caractères, Python est devenu un langage de choix pour le parsing de divers types de fichiers, y compris le texte, CSV, XML, JSON, et bien d’autres encore.
L’un des principaux avantages de Python pour les tâches de parsing est son vaste écosystème de bibliothèques. Python offre un riche ensemble de modules intégrés pour les opérations sur les fichiers, les expressions régulières et la manipulation des chaînes de caractères, ce qui rend les tâches de parsing simples et efficaces. En outre, il existe de nombreuses bibliothèques tierces fournissant des fonctionnalités spécialisées pour le parser des formats de fichiers spécifiques.
En outre, la syntaxe facile à comprendre de Python en fait un langage convivial pour les tâches de parsing de fichiers. Avec l’infrastructure adéquate, vous êtes en mesure d’extraire, de manipuler et de valider rapidement des données à partir de fichiers aux structures complexes avec le parsing Python. Les capacités multiprocessus de Python permettent également aux développeurs de paralléliser les tâches d’analyse, ce qui améliore les performances et la scalabilité.
Ainsi, si vous souhaitez créer votre propre analyseur syntaxique, nous vous recommandons d’utiliser le langage de programmation Python. Cependant, la création de votre propre analyseur Python peut nécessiter beaucoup de ressources (c’est-à-dire du temps et de l’argent) et des connaissances approfondies en programmation, que votre organisation ne possède peut-être pas. C’est pourquoi nous avons énuméré dans la section suivante quelques solutions qui ne nécessitent pas la construction de votre propre parseur !
Parser automatiquement des informations à partir de fichiers
Les entreprises qui cherchent à réduire les efforts humains, le temps et les dépenses ne peuvent plus se permettre d’extraire manuellement les informations des fichiers et de les saisir dans un système informatique. Cela étant dit, il existe des moyens pour les entreprises d’automatiser le parsing des fichiers à l’aide de diverses technologies. Voici quelques options:
- Logiciel OCR intégré à l’IA
- Applications Web
- Robots et Bots
Logiciel OCR intégré à l’IA
Les logiciels de reconnaissance optique de caractères (OCR) permettent de numériser des documents et d’extraire du texte dans un format lisible par une machine. Cependant, pour automatiser le parsing des fichiers, il est souvent nécessaire d’utiliser un logiciel d’OCR intégrant l’IA. Avec une telle solution, les entreprises peuvent mettre en place un flux de travail rationalisé pour analyser automatiquement les informations contenues dans des fichiers tels que les factures, les reçus, les cartes d’identité, les passeports, les permis de conduire, les formulaires et bien d’autres encore.
L’IA peut être utile à bien des égards, non seulement pour le parsing, mais aussi pour vérifier l’authenticité d’un document, détecter les fraudes ou masquer des données sensibles. C’est pourquoi il serait plus avantageux pour les entreprises d’intégrer un logiciel d’OCR en Cloud plutôt que de développer en interne un simple parseur avec de nombreuses limitations en utilisant Python ou d’autres langages de programmation.
Applications Web
Il existe plusieurs applications web et outils en ligne permettant aux entreprises parser des fichiers gratuitement. Certains de ces outils peuvent analyser automatiquement les données de fichiers tels que les PDF, les CSV, les feuilles de calcul Excel et d’autres formats de fichiers courants. Souvent, les utilisateurs peuvent télécharger leurs fichiers vers ces applications web, qui utilisent ensuite des algorithmes d’analyse pour extraire les données pertinentes et les convertir dans un format utilisable. Consultez notre convertisseur d’images en texte gratuit, par exemple!
Il est important de connaître les limites de ces outils. Ils peuvent être utiles pour de petits volumes d’analyse de fichiers, mais le nombre de fichiers pouvant être parser avec un compte gratuit est limité et les coûts peuvent s’accumuler rapidement. La confidentialité des données est également une préoccupation importante. Ces outils en ligne gratuits accordent-ils vraiment la priorité à la sécurité des données des utilisateurs ou cherchent-ils avant tout à gagner rapidement de l’argent ? Bien qu’il soit prudent d’éviter de se fier uniquement à ces outils, il peut être intéressant d’explorer cette option.
Robots et bots
Les robots et les bots, dans le contexte de l’automatisation des processus robotiques (RPA), sont des programmes logiciels qui peuvent être utilisés pour le parsing automatique de données à partir de fichiers. Dans le cadre de la RPA, les robots ou bots gèrent l’automatisation des tâches manuelles, éliminant ainsi le besoin d’une intervention humaine.
L’un des principaux avantages de l’utilisation de robots RPA pour l’analyse de données à partir de fichiers est leur haut niveau de précision et d’efficacité. Les robots RPA peuvent travailler 24 heures sur 24 et 7 jours sur 7 sans intervention humaine, ce qui réduit le risque d’erreurs dues à la saisie manuelle des données et augmente la productivité. En outre, ils peuvent se connecter sans effort à diverses sources de données, API et intégrations tierces, ce qui leur confère un avantage significatif dans la collecte et le traitement des données à analyser de diverses manières.
Parser des fichiers avec Klippa DocHorizon
Le logiciel d’OCR Klippa DocHorizon, à l’épreuve du temps et alimenté par l’IA, permet à diverses entreprises d’automatiser leurs processus de traitement de documents, incluant le parsing de fichiers. Il s’agit d’une solution d’analyse de fichiers puissante et versatile qui permet aux entreprises d’extraire efficacement des données précieuses à partir de divers formats de fichiers.
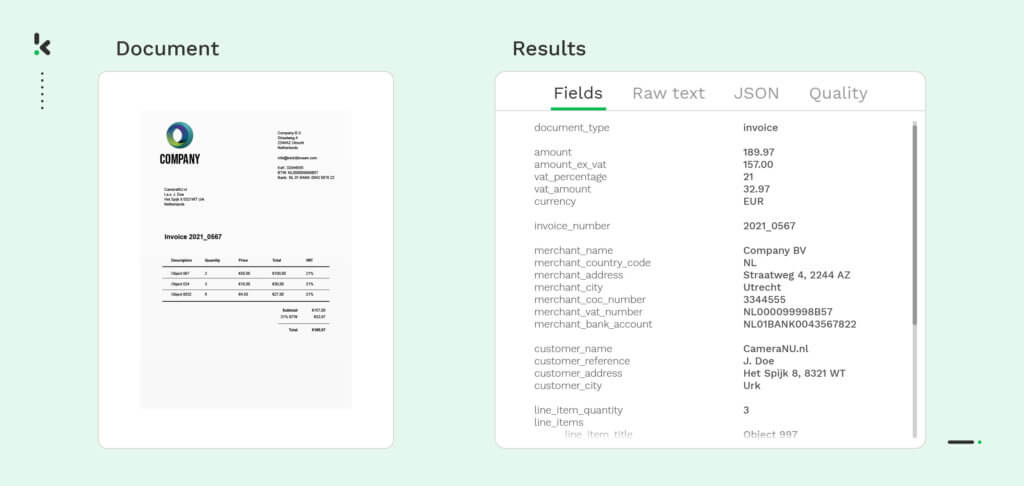
Outre le parsing des fichiers, DocHorizon peut vérifier l’authenticité d’un document, détecter les documents frauduleux, classer les documents et masquer les données sensibles automatiquement, ce qui rend votre processus de traitement des documents évolutif. Vous pouvez intégrer DocHorizon dans votre flux de travail ou vos systèmes logiciels existants à l’aide de notre API.
Si vous souhaitez doter vos applications mobiles actuelles de fonctionnalités d’OCR ou le parsing des fichiers, vous pouvez également consulter nos SDK de numérisation mobile. Nos solutions offrent de nombreux avantages, notamment:
- Jusqu’à 99 % d’extraction de données grâce à l’OCR interne alimentée par l’IA
- Évolutivité au-delà de votre imagination
- Réduction des frais administratifs grâce à l’automatisation
- Réduction des erreurs de saisie des données
- Conformité avec les réglementations sur la confidentialité des données puisque les données traitées ne sont pas stockées sur les serveurs de Klippa.
Prêt à transformer vos données non structurées en informations exploitables ? Planifiez une démonstration gratuite en utilisant le formulaire ci-dessous ou contactez l’un de nos experts pour plus d’informations !