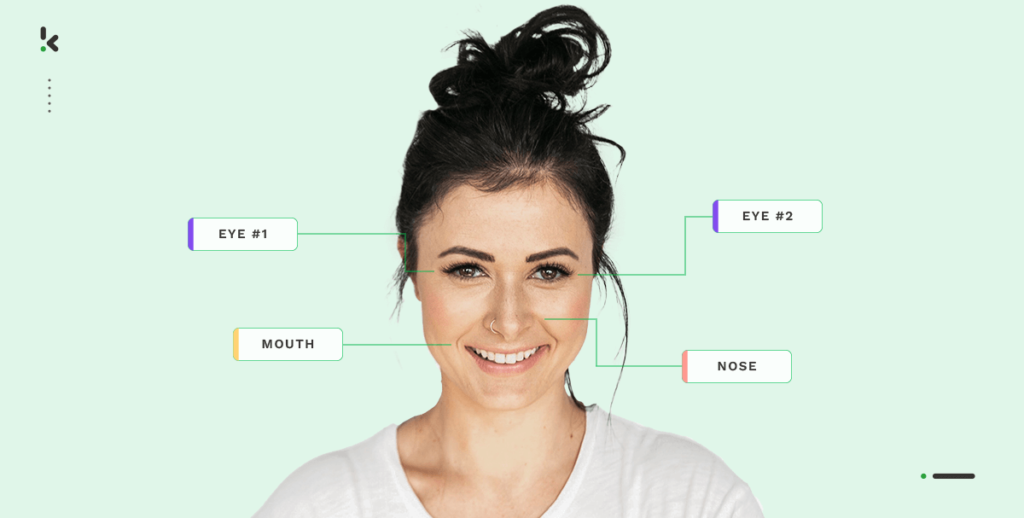
L’intelligence artificielle (IA) et l’apprentissage automatique (ML) sont des technologies en plein essor qui nous permettent d’inventer des choses incroyables. Pensez à une voiture à conduite autonome ou à la fonction de déverrouillage par identification faciale de votre smartphone. Avez-vous déjà réfléchi à la manière dont cela fonctionne réellement?
Pour qu’une machine soit capable de prendre la décision de ne pas foncer dans l’arbre suivant, elle doit être entraînée à comprendre des informations spécifiques. Pour développer de telles machines et applications automatisées, une énorme quantité de données d’entraînement est nécessaire. Les entreprises peuvent soit acheter des données d’entraînement, soit engager une équipe d’experts, appelés annotateurs de données, capables de travailler avec des ensembles de données brutes.
En général, l’annotation des données est un processus complexe et coûteux qui doit être mené par des experts afin d’obtenir un résultat satisfaisant.
De nombreuses entreprises actives dans le domaine de l’IA ont du mal à gérer l’annotation des données et ne savent pas par où commencer. Par conséquent, dans ce blog, nous allons expliquer ce qu’est l’annotation des données, quels types de méthodes d’annotation des données sont disponibles, puis nous verrons pourquoi l’annotation des données est si nécessaire de nos jours.
Commençons.
Qu’est-ce que l’annotation de données?
En bref: l’annotation des données est le processus d’étiquetage des données disponibles dans une vidéo, une image ou un texte. Les données sont étiquetées afin que les modèles puissent facilement comprendre une source de données donnée et reconnaître certains formats, objets, informations ou modèles à l’avenir.
Pour que le modèle puisse comprendre et donner un sens aux images, vidéos et autres formats présentés, il utilise la vision par ordinateur. La vision par ordinateur est un sous-domaine de l’intelligence artificielle (IA) qui permet aux logiciels et aux ordinateurs d’observer et de donner un sens aux données visuelles numériques. Mais comment cela se rapporte-t-il à l’annotation des données?
Afin d’apprendre à la vision par ordinateur à reconnaître des objets, des modèles ou d’autres informations, les données doivent être annotées avec précision ou, en termes plus techniques, elles doivent être équipées d’un modèle d’apprentissage automatique établi. Pour ce faire, on utilise des méthodes et des outils adéquats.
En général, que l’annotation des données soit effectuée manuellement ou automatiquement, la procédure se compose de deux étapes:
- Étiquetage des données
- Contrôles de qualité et audits
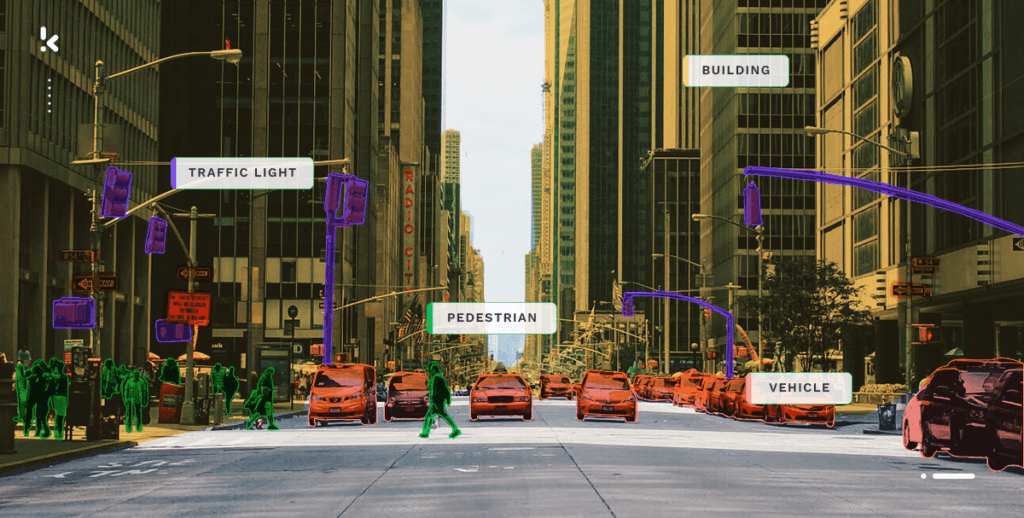
La première étape de l’annotation de données consiste à étiqueter les données des images, des vidéos ou du texte. Dans ce contexte, l’étiquetage des données consiste à ajouter une ou plusieurs étiquettes informatives aux données brutes (images, texte, vidéo, etc.), pour fournir un contexte, afin qu’un modèle d’apprentissage automatique puisse en tirer des enseignements. Comme dans le visuel dessous, les feux de circulation, les piétons, les véhicules et les bâtiments sont étiquetés pour renseigner le modèle.
La deuxième étape commence après l’étiquetage des données. Ici, l’ensemble de données annotées est vérifié pour l’authenticité et la précision. Cette étape est très importante. Sinon, le modèle établi est formé avec des données incorrectes, ce qui peut entraîner des procédures de ré-apprentissage coûteuses.
Maintenant que nous avons une idée générale de l’annotation des données, nous voulons examiner de plus près les différents types d’annotation.
Types d’annotation de données
Comme indiqué précédemment, le processus d’annotation des données peut être appliqué à différents types de présentations. Cela signifie que différents types de méthodes d’annotation des données sont utilisés. Pour des raisons de lisibilité du blog, nous nous concentrerons sur trois des différentes méthodes d’annotation des données. Gardez à l’esprit que cette liste n’est pas exhaustive:
- Annotation d’image
- Annotation de vidéo
- Annotation de texte
Annotation d’image
Pour un large éventail d’applications telles que la vision par ordinateur, la vision robotique, la reconnaissance faciale et les solutions reposant sur l’intelligence artificielle, l’annotation des images permet de les interpréter. Cependant, avant que cela ne soit applicable, le modèle d’IA doit être entraîné avec des milliers d’images étiquetées.
L’entraînement peut être réalisé en attribuant des métadonnées, telles que des identifiants, des légendes et des mots-clés, à des centaines d’images. Avec un entraînement efficace, la précision du modèle d’IA augmente et vous permet de l’utiliser à de nombreuses fins (par exemple, véhicules autopilotés, conditions médicales auto-identifiées).
L’annotation d’images elle-même comporte à nouveau différents types de méthodes d’annotation, tels que:
- Cadres de délimitation → Tracer un rectangle autour de l’objet que vous souhaitez annoter dans une image donnée. Les bords de la boîte englobante doivent toucher les pixels les plus éloignés de l’image étiquetée afin de garantir la plus grande précision possible.

- Cuboïdes 3D → Cette méthode est très similaire à l’annotation des boîtes englobantes. La seule différence est que l’utilisateur doit tenir compte du facteur de profondeur. Elle peut être utilisée pour annoter des avions ou des voitures sur une image.

- Polygones → Lors de l’utilisation de cadres de délimitation ou de cuboïdes 3D, certains objets peuvent être inclus involontairement dans la zone annotée. L’outil polygone permet de tracer une ligne autour de l’objet spécifique de l’image qui doit être annoté.

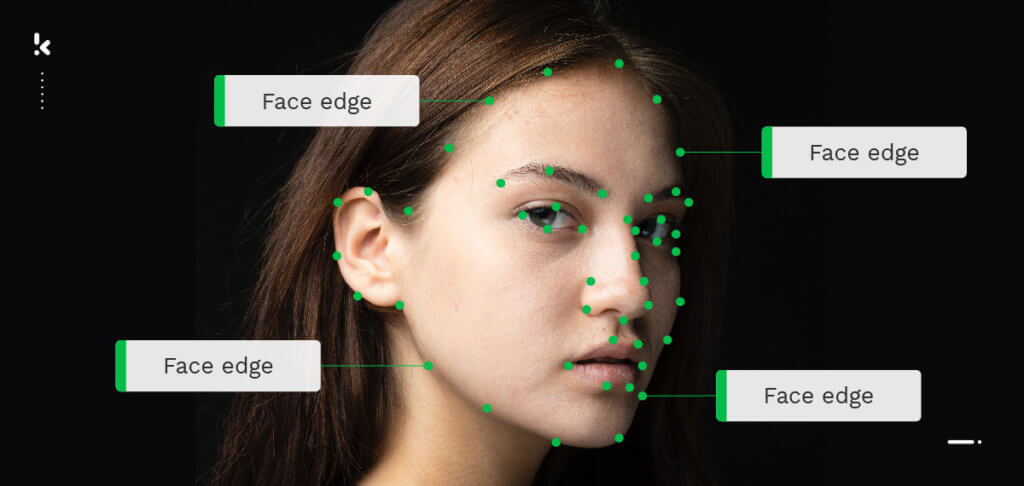
- Outil Keypoint → Un objet peut être annoté par une série de points. Cette technique est souvent utilisée pour la détection de gestes ou le suivi de mouvements.
Avec cela en tête, regardons maintenant l’annotation vidéo.
Annotation de vidéo
L’annotation des vidéos est effectuée image par image afin de rendre les objets annotés reconnaissables pour les modèles d’apprentissage automatique. En général, elle utilise les mêmes techniques que l’annotation d’images (par exemple, les cadres de délimitation) pour détecter ou identifier les objets souhaités.
Cette méthode d’annotation est une technique essentielle pour les tâches de vision artificielle telles que la localisation et le suivi d’objets, dans lesquelles un algorithme peut suivre le mouvement d’un objet. Par conséquent, l’annotation vidéo est utile pour plusieurs industries telles que le secteur médical, l’industrie manufacturière et la gestion de la circulation.
Le dernier type d’annotation de données est l’annotation de texte. Le texte est la catégorie de données la plus couramment utilisée, car la plupart des entreprises dépendent fortement du texte dans divers processus commerciaux.
Annotation de texte
L’annotation de texte consiste à ajouter des métadonnées ou des étiquettes à des morceaux de texte. Examinons de plus près ce que cela signifie.
Ajouter des métadonnées
L’ajout de métadonnées consiste à fournir des informations pertinentes à l’algorithme d’apprentissage. Il peut ainsi établir des priorités et se concentrer sur certains mots.
Exemple: « Voici la facture (type_de_document) pour le nouveau ordinateur (commande) que vous avez commandé hier (heure). »
Les métadonnées ajoutées entre parenthèses fournissent des informations pertinentes à l’algorithme d’apprentissage, ce qui lui permet de détecter à l’avenir les informations pour lesquelles il a été formé.
Attribution d’étiquettes
L’ajout d’étiquettes permet d’attribuer à une phrase des mots qui en décrivent le type. Une phrase peut par exemple être décrite par des sentiments ou des aspects techniques.
Exemple: « Le produit ne répond pas à mes besoins, je veux le retourner. » Ici, l’étiquette « mécontent » pourrait être attribuée.

Cela aide l’algorithme à comprendre le sentiment et l’intention d’un texte et est étroitement lié à la reconnaissance des entités nommées. Voyons pourquoi.
Reconnaissance d’entités nommées (NER)
La reconnaissance des entités nommées est utilisée pour rechercher des mots sur la base de leur signification. Elle vise à détecter des entités nommées et des expressions prédéfinies dans une phrase. En général, la reconnaissance des entités nommées est utile pour extraire, classer et catégoriser des informations.
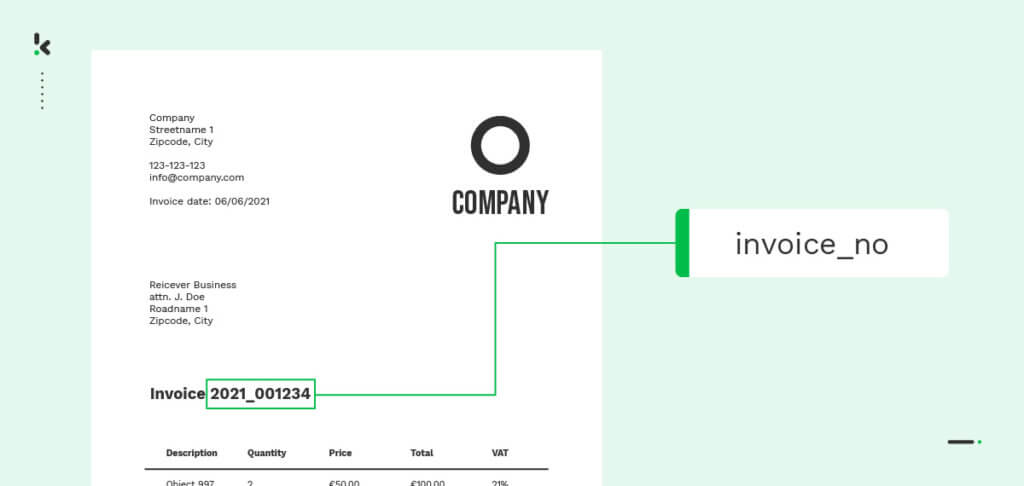
Prenons l’exemple d’une facture. En entraînant le modèle à reconnaître le terme « numéro de facture » et les caractéristiques d’un numéro de facture (par exemple, le nombre de chiffres), il est possible de classer le document comme étant une facture. Le même principe s’applique à des mots différents dans des documents différents, ce qui signifie que vous pouvez utiliser la méthode de reconnaissance des entités nommées pour classer divers documents sur la base de champs de données.
En outre, un algorithme d’IA peut être spécifiquement formé pour comprendre le sentiment et l’intention d’une phrase, ce qui est très important pour comprendre le comportement humain. Voyons ce que cela signifie.
Annotation du sentiment
Comme indiqué précédemment, l’annotation des sentiments consiste à attribuer au texte des étiquettes représentant les émotions humaines. À cette fin, des étiquettes telles que triste, heureux, frustré ou en colère sont utilisées. Elle peut ensuite être utilisée pour l’analyse des sentiments, par exemple dans le secteur de la vente de détail, afin de comprendre la satisfaction des clients.
Annotation d’intention
L’annotation de l’intention signifie essentiellement que des étiquettes sont attribuées aux phrases qui expriment une certaine intention ou un certain besoin. Cela peut être très utile, par exemple, pour le service à la clientèle.
Prenons l’exemple d’un chatbot. Lorsqu’un client soumet la phrase « J’ai des difficultés à payer avec ma carte de crédit », la personne peut immédiatement être dirigée vers l’équipe financière.
Cela est possible parce que l’algorithme a été entraîné avec des centaines de phrases qui expriment un besoin similaire.
Des mots comme « problème » expriment une émotion (sentiment) du client. De plus, des mots comme « carte de crédit » étaient auparavant étiquetés comme « méthode de paiement » ou des étiquettes similaires, ce qui permet à l’algorithme de diriger le client vers le service financier.
Avant d’expliquer pourquoi l’annotation des données est nécessaire, nous souhaitons approfondir la différence entre l’annotation automatisée des données et l’annotation manuelle des données.
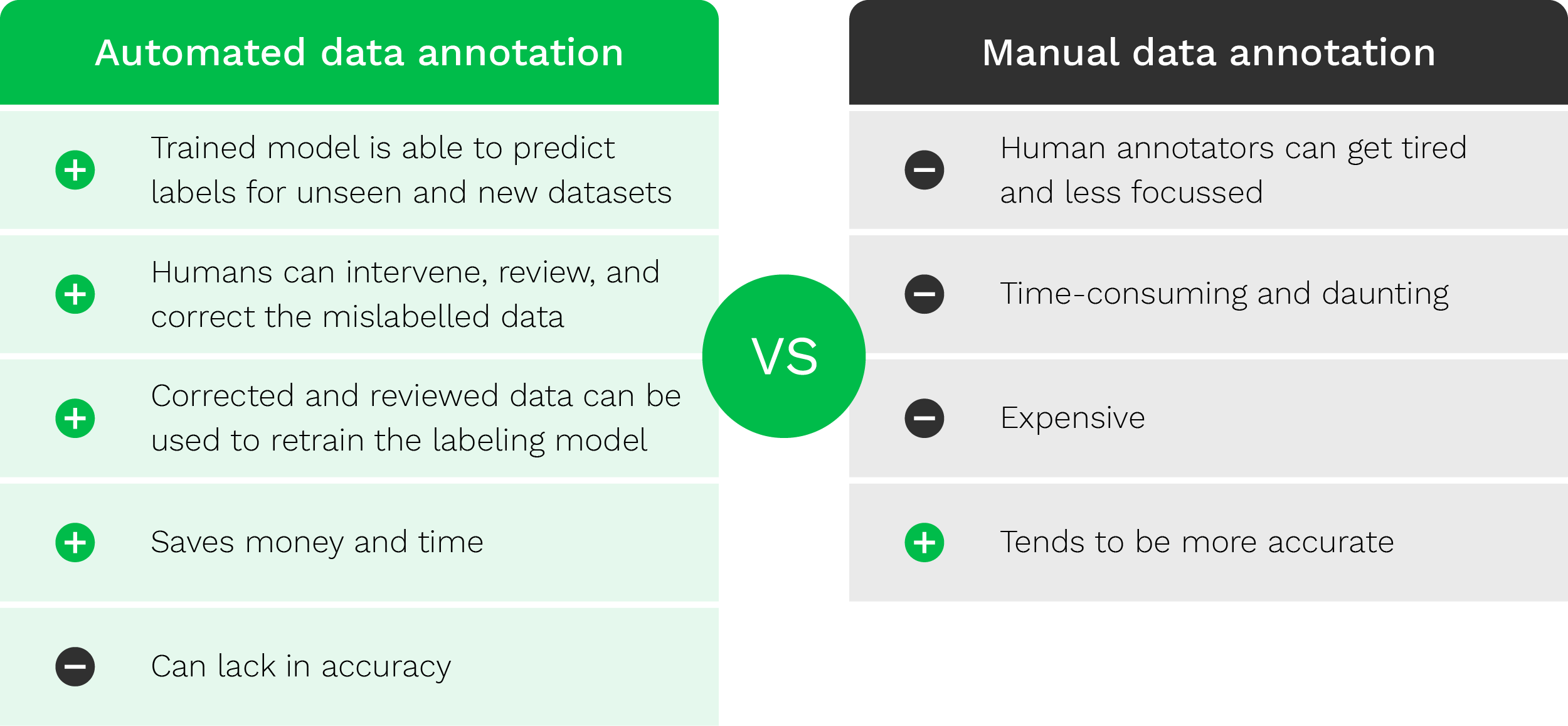
Annotation automatisée des données vs. annotation manuelle des données
L’annotation manuelle des données, comme son nom l’indique, implique des humains et fonctionne de la manière suivante:
- L’annotateur de données reçoit des ensembles de données brutes (vidéos, images, textes, etc.) pour l’annotation
- Sur la base des spécifications et du résultat souhaité, les annotateurs savent quelle méthode (boîte englobante, outil de point clé, etc.) utiliser pour annoter les éléments pertinents
- L’expert en annotation de données étiquette manuellement tous les éléments requis
- Après cela, l’ensemble de données est prêt à être utilisé pour former un modèle
L’annotation d’une image peut prendre jusqu’à 15 minutes en fonction de la qualité du document fourni, de l’outil d’annotation et des exigences. Imaginez que vous ayez un projet comportant jusqu’à 50 000 images. Cela signifie qu’un annotateur expert passe 12 500 heures à annoter ces images. Il doit y avoir une meilleure solution.
Annotation automatisée des données
Afin d’accélérer l’annotation des données, les modèles d’étiquetage automatique des données sont de plus en plus répandus. Avec l’étiquetage automatique des données, les systèmes d’intelligence artificielle prennent en charge le processus d’annotation des données.
Cela fonctionne grâce à des règles et des conditions prédéfinies par les humains. Un ensemble de données est soumis à ces règles prédéfinies afin de valider une étiquette spécifique. Bien que cette méthode soit plus efficace, un problème subsiste. Lorsque les structures de données changent fréquemment, il devient difficile de définir des conditions et des règles, ce qui fait qu’il est presque impossible pour un modèle de prendre une décision en connaissance de cause.
C’est pourquoi un effort combiné de l’intelligence humaine et de l’intelligence artificielle vous donnera probablement le meilleur résultat possible. Avec l’aide d’un humain dans la boucle (human in the loop), les résultats du modèle d’IA sont constamment validés, vérifiés et optimisés, pendant que le modèle s’occupe de l’étiquetage des données.
Pour donner un aperçu rapide de la différence entre l’annotation automatisée et manuelle des données, nous présentons le tableau ci-dessous.
Mais pourquoi s’intéresser à tout cela? Il y a plusieurs raisons pour lesquelles l’annotation des données est nécessaire. Jetons y un coup d’œil.
Pourquoi l’annotation des données est-elle nécessaire?
Notre besoin continuel d’innovation rend l’annotation des données nécessaire. Sinon, comment une voiture pourrait-elle se conduire toute seule? Sans l’annotation des données, chaque image serait identique pour les machines, car elles n’ont aucune connaissance inhérente sur quoi que ce soit dans le monde.
En d’autres termes, sans formation au modèle de ce qu’est un véhicule, une rue, un trottoir ou un piéton, la voiture autopilotée foncerait sans réfléchir sur tout ce qui croise son chemin.
De même, de nombreuses entreprises forment des modèles d’IA pour identifier les types de documents afin d’automatiser les processus de catégorisation et d’extraction de données. Comme de nombreuses entreprises traitent avec des fournisseurs, prenons l’exemple des factures. Pour que le modèle catégorise correctement le type de document, les caractéristiques d’une facture sont d’abord étiquetées, puis transmises à l’algorithme.
Cela ne se limite pas aux factures et peut s’appliquer à n’importe quel type de document. Pour vous, cela signifie que tous vos flux de travail liés aux documents pourraient être optimisés et soulager votre équipe de la tâche d’identifier et de catégoriser les documents eux-mêmes.
Dans cette optique, examinons rapidement les principaux avantages de l’annotation des données.
Les principaux avantages de l’annotation des données
En dehors du gain de temps et d’argent, l’annotation des données présente encore d’autres avantages. Ces avantages sont les suivants:
- Efficacité accrue → L’étiquetage des données permet aux systèmes d’apprentissage automatique d’être mieux formés, ce qui les rend plus efficaces dans la reconnaissance d’objets, de mots, de sentiments, d’intentions, etc.
- Un degré de précision plus élevé → Un étiquetage correct des données permet d’obtenir des données plus précises pour former un algorithme. Cela se traduira à l’avenir par une plus grande précision dans l’extraction des données.
- Réduction de l’intervention humaine → Plus l’annotation des données est précise, plus les résultats du modèle d’IA sont bons. La précision des résultats de l’algorithme signifie que moins d’intervention humaine est nécessaire, ce qui réduit les coûts et permet de gagner du temps.
- Évolutivité → Cela s’applique à l’annotation automatisée des données, qui vous permet de mettre à l’échelle les projets d’annotation des données afin d’améliorer les modèles d’IA et de ML.
À côté de ses avantages, chaque solution a ses limites. C’est pourquoi il est important d’en parler ensuite pour avoir une vue d’ensemble.
Les limites de l’annotation des données
Même si l’annotation des données est essentielle à l’entraînement des modèles d’IA et de ML, elle a aussi ses limites. Voyons quelles sont ces limites:
- Les modèles d’IA et de ML ont besoin d’une quantité énorme de données étiquetées pour apprendre. Par conséquent, les entreprises doivent embaucher un nombre considérable de travailleurs capables de générer cet énorme volume de données étiquetées. Cela n’est pas seulement coûteux, mais limite également l’efficacité et la productivité de ces entreprises.
- Souvent, les entreprises ont un accès limité aux outils et à la technologie appropriés qui peuvent fournir un processus d’annotation de données précis. Cela signifie que ces entreprises se retrouvent avec des données inexactes et un processus d’apprentissage des modèles lent.
- Les modèles ML sont très sensibles. La moindre erreur peut coûter très cher aux entreprises. Si le modèle est formé avec des données inexactes, il apprendra de la mauvaise manière et prédira donc les données de manière incorrecte dans le futur.
- Un manque de connaissance des processus peut conduire à l’incapacité de se conformer aux directives en matière de sécurité des données. Les entreprises sont souvent confrontées à des données sensibles, telles que l’identification de visages, qui doivent être traitées avec la plus grande sécurité. Si l’étiquetage des données est mal fait, des informations erronées ou de petites erreurs peuvent conduire à des résultats terribles.
Vous pouvez constater que l’annotation des données est une procédure délicate qui peut conduire à des modèles d’IA mal formés. Si cela se produit, votre voiture auto-conduite s’écrasera contre le prochain arbre ou écrasera un piéton innocent. Comme nous ne voulons absolument pas que cela se produise, il est judicieux de faire appel à d’autres entreprises qui ont des heures d’expérience dans l’annotation des données.
Klippa est l’une des entreprises qui a passé des milliers d’heures à annoter des données pour améliorer son logiciel basé sur l’IA.
Que peut faire Klippa pour vous?
Chez Klippa, nous avons formé nos modèles pour aider les entreprises à automatiser le traitement des documents. Grâce à de nombreuses années d’entraînement de notre moteur d’OCR alimenté par l’IA, vous pouvez être sûr que notre logiciel, DocHorizon, fonctionne de manière fiable et précise. En utilisant notre solution, vous pouvez vous épargner la tâche ardue de l’annotation des données tout en profitant de tous les avantages.
Klippa DocHorizon
En général, Klippa DocHorizon peut transformer n’importe quelle image en texte. En outre, ce logiciel intelligent peut extraire, classer et vérifier les données de toutes sortes de documents tels que les reçus, les factures, les passeports et les cartes d’identité. Cela signifie que vous pouvez obtenir n’importe quel champ de données automatiquement extrait et stocké dans votre base de données.
Avant de stocker les données dans votre base de données, notre logiciel de traitement intelligent des documents (IDP) est capable de détecter la fraude documentaire et de masquer les données sensibles pour se conformer aux exigences réglementaires.
Si vous souhaitez compléter votre logiciel existant ou extraire des données à partir d’objets autres que des documents, nous pouvons certainement vous aider.
SDK de détection d’objets
Notre SDK de détection d’objets peut être entraîné à reconnaître tout ce dont vous avez besoin. Qu’il s’agisse d’un compteur ou d’une facture, avec suffisamment d’ensembles de données étiquetées, notre équipe d’annotation des données peut aider les clients à entraîner notre modèle de détection d’objets à reconnaître n’importe quel objet dont vous avez besoin.
Cela signifie que vous pouvez fournir à votre équipe une solution fiable qui vous permet de capturer des données à l’aide de téléphones portables.

Vous êtes curieux de découvrir notre solution et vous voulez en savoir plus? Laissez-nous vous montrer comment fonctionne notre logiciel. Il vous suffit de planifier une démonstration gratuite ci-dessous ou de contacter l’un de nos experts pour plus d’informations.