En 2023, une quantité incroyable de 3,5 quintillions d’octets de données sera créée chaque jour. Plutôt étonnant, n’est-ce pas? Ces données sont essentielles à la croissance des organisations, car elles facilitent la vie des gens, résolvent les problèmes des organisations et stimulent l’innovation.
Mais il y a un problème: la plupart des données sont bloquées dans des formats non structurés, tels que des documents scannés ou des papiers manuscrits. Il est donc pratiquement impossible pour les entreprises d’utiliser les données de manière efficace.
La difficulté réside dans le fait que les entreprises ont besoin de ces fichiers de données brutes et de les transformer dans d’autres formats pour les transmettre d’un logiciel à l’autre. Pour ce faire, elles doivent trouver une solution qui rende les données accessibles à toutes sortes d’entités. C’est là que l’analyse de données entre en jeu.
À ce stade, le parsing (analyse syntaxique) des données peut vous paraître comme un concept abstrait. C’est pourquoi, dans le paragraphe suivant, nous expliquerons ce qu’est l’analyse syntaxique des données, nous continuerons à présenter les différents types d’analyse syntaxique des données et nous préciserons pourquoi l’analyse syntaxique des données est si essentielle.
Commençons.
Qu’est-ce que le parsing (analyse syntaxique) de données?
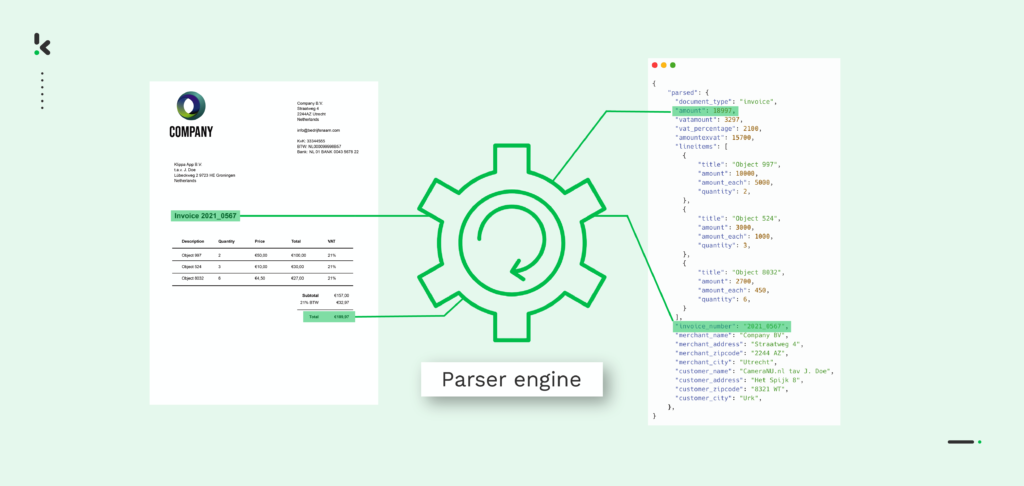
En termes simples: Le parsing des données est le processus de conversion des données d’un format à un autre. Par exemple, supposons que vous ayez un fichier PDF et que vous ayez besoin de le convertir en fichier JSON. Dans ce cas, vous avez besoin d’un analyseur de données capable de transformer des données PDF brutes en un format lisible par une machine.

En général, le parsing des données est appliqué comme l’étape suivante après que les données ont été extraites d’un document. La plupart du temps, les données extraites sont dans un format et doivent être converties dans un autre format, afin qu’elles puissent être enregistrées dans votre base de données ou transmises à un logiciel tiers.
La conversion d’un format de fichier à un autre est possible à l’aide d’un sous-domaine de l’IA, appelé Traitement du Langage Naturel (NLP), dans lequel une chaîne de symboles, de caractères spéciaux et de structures de données est analysée. Sur la base de règles définies par l’utilisateur, l’information est d’abord structurée, puis organisée, ce qui donne un sens aux données extraites.
Il est important de garder à l’esprit qu’en fonction des structures contextuelles des données extraites, différentes approches d’analyse de données peuvent être appliquées. Voyons comment fonctionnent ces différentes approches.
Différents types de parsing de données
En général, l’analyse syntaxique des données adopte deux approches différentes: l’analyse grammaticale des données et l’analyse des données pilotée par des données.
Parsing grammaticale des données
Comme son nom l’indique, l’analyse grammaticale des données base le processus d’analyse sur un ensemble de règles grammaticales formelles. Il s’agit de fragmenter les phrases à partir de données non structurées, puis de les transformer en un format structuré et facile à comprendre.
Néanmoins, cette approche présente un problème: elle manque de robustesse. Pour surmonter ce problème, les restrictions grammaticales sont souvent assouplies. Cela signifie que les phrases qui n’entrent pas dans le champ d’application de la grammaire habituelle peuvent être exclues de l’analyse syntaxique des données.
Comme l’analyse grammaticale des données présente des limites et des incohérences, une autre méthode d’analyse des données a été trouvée. C’est là où intervient l’analyse syntaxique des données pilotée par les données.
Parsing de données dirigé par les données
En général, l’analyse syntaxique pilotée par les données utilise des analyseurs statistiques intelligents et des banques d’arbres modernes pour couvrir le plus grand nombre de langues possible. Cela vous permet d’analyser des langues de conversation et des phrases qui exigent une grande précision, même si elles ne sont pas étiquetées et sont spécifiques à un domaine.
Remarque: une banque d’arbres (treebank) améliore les modèles de NLP, de sorte qu’un logiciel d’intelligence artificielle est capable de comprendre un texte écrit. Une analyse syntaxique statistique peut utiliser le modèle NLP pour comprendre les différentes interprétations possibles d’une phrase et restituer la plus probable.
Dans l’analyse syntaxique pilotée par les données, deux approches peuvent être mises en œuvre:
- Approche fondée sur des règles
- Approche fondée sur l’apprentissage
Approche fondée sur des règles
L’approche basée sur des règles convient aux documents structurés tels que les factures fiscales ou les bons de commande. Les règles définies aident l’utilisateur à déterminer un modèle qui sert de référence à l’analyseur pour extraire les données d’un document.
Le principal inconvénient de cette approche est la dépendance stricte aux modèles prédéfinis, ce qui signifie que même un format de document légèrement différent entraînera un échec de l’analyse syntaxique des données. Quel pourrait être le moyen d’analyser les données de manière plus flexible?
Approche fondée sur l’apprentissage
La réponse est la suivante: Une approche de l’analyse syntaxique des données basée sur l’apprentissage. Cette approche repose fortement sur l’apprentissage automatique (ML) et le traitement du langage naturel (NLP) et est généralement utilisée pour extraire des données à partir de n’importe quel type de document.
Comme le modèle est entraîné à partir de divers documents non structurés, la capacité à reconnaître facilement les champs importants et à en extraire des données est renforcée.
Dans la pratique, une combinaison des deux approches, basée sur les règles et basée sur l’apprentissage, est utilisée pour effectuer l’analyse syntaxique des données. Cette combinaison vous permet de traiter n’importe quel document avec n’importe quel type de format de présentation et ne vous limite pas à un seul format de présentation.
Dans cette optique, voyons comment l’analyse syntaxique des données est utilisée dans différents secteurs d’activité.
Cas d’utilisation du parsing de données
L’analyse syntaxique des données est utilisée dans plusieurs secteurs pour convertir des données piégées dans des formats inutilisables en données prêtes à l’emploi. Pour des raisons de lisibilité, nous nous concentrerons sur quatre secteurs seulement, mais n’oublions pas que cette liste est loin d’être complète:
- Industrie financière
- Soins de santé
- Juridique
- Transport & Logistique
Industrie Financière
Les banques et autres institutions financières traitent des millions de documents de clients tels que des cartes d’identité, des relevés bancaires et des demandes d’inscription. Tous ces documents doivent être analysés et les informations pertinentes doivent être stockées dans la base de données de la banque.
De même, toute sorte d’entreprise traite des factures et des reçus qui sont souvent traités manuellement et sauvegardés dans différents formats (PNG, PDF, etc.). Il est donc très difficile d’effectuer des recherches dans les données et de les utiliser efficacement.
Pour améliorer les processus financiers, un analyseur syntaxique de données peut être utilisé dans les cas suivants:
- Saisie automatisée des données
- Accueil des clients
- Vérification de l’exhaustivité des documents
- Automatisation KYC
- Traitement automatisé des factures
- Conversion de PDF en Excel
- Extraction de données des PDF

Ne vous inquiétez pas si votre cas n’est pas mentionné ici. Il existe de nombreux autres cas d’utilisation pour le secteur financier.
Soins de Santé
Le secteur des soins de santé est souvent confronté à une pénurie de ressources, à de longues heures de travail et à d’énormes tâches administratives. Cela peut rapidement conduire à des erreurs dans les dossiers des patients, les traitements de suivi et les prescriptions, ce qui se traduit par un dommage grave, ou même le décès du patient.
En outre, l’accueil des patients est rempli de toutes sortes de documents, ce qui oblige les employés du secteur de la santé à passer beaucoup de temps à saisir les données des formulaires dans les ordinateurs.
Dans le secteur des soins de santé, un analyseur de données peut être utile dans les cas suivants:
- Intégration automatisée des patients
- Extraction de données à partir des dossiers des patients
- Numérisation de la carte d’assurance maladie

Juridique
Les avocats coûtent cher, ce qui signifie que les cabinets d’avocats veulent absolument qu’ils consacrent leur temps à résoudre des affaires plutôt qu’à trier des quantités infinies de documents. Mais comme les avocats reçoivent toutes sortes de documents de leurs clients dans différents formats, ils passent beaucoup de temps à les trier. Cela les rend très inefficaces et lents.
En outre, les avocats servent plusieurs clients en même temps. Il est donc essentiel que tous les documents soient correctement organisés et classés. Dans le cas contraire, il est pratiquement impossible de garder une vue d’ensemble et de suivre les différentes affaires.
En outre, la plupart des documents des clients contiennent des informations sensibles qui doivent être protégées contre les violations de données et la fraude.
Dans le cas du secteur juridique, l’analyse des données peut s’avérer utile dans les cas suivants:
- Collection et organisation des données
- Classification des documents
- Extraction automatisée des données
- Anonymisation des informations

Transport & Logistique
Toute entreprise qui vend des produits ou des services en ligne doit gérer un grand nombre d’informations relatives à l’expédition et à la facturation. Il faut donc gérer les étiquettes d’expédition, les fiches d’emballage, les preuves de livraison, etc.

Un analyseur syntaxique de données peut être utilisé dans des cas comme celui-ci:
- Saisie automatisée des données
- Contrôles de conformité
- Traitement automatisé des factures
- Détection de la fraude documentaire
- Gestion des paquets
En examinant ces différents cas d’utilisation, il devient évident que l’analyse syntaxique des données est bénéfique pour plusieurs industries. L’automatisation de l’analyse des données permet d’améliorer le processus et de le rendre encore plus efficace. Voyons comment l’analyse syntaxique des données peut être automatisée.
Comment automatiser le parsing des données?
De nos jours, vous êtes probablement obligé de réduire le temps, les efforts humains et les dépenses de votre entreprise partout où vous le pouvez. Pour y parvenir, l’automatisation semble être la seule solution. Comme nous l’avons vu dans les cas d’utilisation présentés, l’analyse de données en elle-même apporte déjà de grands avantages tels que l’optimisation du flux de travail. Afin d’améliorer l’analyse des données, nous pouvons automatiser le processus.
Examinons les différentes façons d’automatiser l’analyse syntaxique des données:
- Logiciel OCR classique
- Applications Web
- Robots & RPA
Logiciel OCR classique
Le logiciel OCR classique est une solution assez simple pour automatiser les processus. Il possède toutes les fonctions et instructions de base pour accomplir le travail. Mais ses fonctionnalités sont limitées.
Par conséquent, un logiciel d’OCR classique est utilisable pour les petits fichiers et pour convertir un simple PDF en JSON, par exemple. Cependant, des tâches telles que l’analyse syntaxique de tableaux ou la lecture d’images ne peuvent pas être effectuées, car elles nécessitent des bibliothèques plus puissantes, qui consomment plus de puissance de calcul et de données.
Applications Web
Les applications web sont souvent utilisées pour les interfaces utilisateur (UI) afin d’automatiser le processus d’analyse des données. Pour opérer sur certains types de fichiers, un langage de base spécifique, tel que Python ou Java, est choisi. Toutes les communications entre l’interface utilisateur, le backend et les autres bases de données se déroulent principalement par l’intermédiaire de la base de données.
Si le site web est opéré sur une solution « cloud » puissante, l’OCR peut être intégré pour effectuer les procédures d’analyse des données. Néanmoins, cette solution peut prendre beaucoup de temps, car elle comporte de nombreuses étapes et requêtes sur l’ensemble du web.
Robots & RPA
L’automatisation robotique des processus (RPA) est l’un des derniers développements en matière d’automatisation. Au lieu que les humains effectuent des tâches manuelles, les robots se chargent d’automatiser ces tâches. Ils sont équipés d’algorithmes intelligents qui leur permettent d’apprendre et de minimiser les erreurs à chaque itération.
L’un des principaux avantages est que ces robots peuvent être connectés à différentes sources de données, API et autres intégrations tierces, ce qui vous permet d’analyser les données différemment.
Maintenant que nous avons expliqué comment l’analyse syntaxique des données peut être automatisée, examinons les avantages de l’analyse syntaxique des données.
Les avantages du parsing de données
En plus de l’avantage le plus important de l’analyse de données, à savoir la possibilité de naviguer dans une énorme quantité de données, d’autres avantages s’appliquent:
- Gagner du temps → Les analyseurs de données aident les entreprises à convertir les données dans un autre format et à automatiser le processus qui, autrement, serait effectué manuellement. Les opérations de l’entreprise sont donc plus rapides et les ressources humaines peuvent être utilisées pour des tâches plus utiles.
- Des données plus accessibles → L’analyse de données rend les données plus accessibles et augmente les possibilités de recherche. Les professionnels sont en mesure d’accéder à toutes les informations nécessaires à partir de l’énorme quantité de données dont ils disposent.
- Modernisation des données → Il peut arriver que les données stockées par les entreprises datent de plusieurs années et ne soient donc pas disponibles dans des formats modernes. Mais ces données peuvent encore contenir des informations précieuses pour l’entreprise. L’analyse syntaxique des données peut rapidement modifier le format de ces données et permettre aux entreprises d’utiliser les informations de manière efficace.
Après avoir vu ce qu’est l’analyse de données, dans quels cas elle est utilisée et quels avantages elle peut apporter, vous vous demandez peut-être comment accéder à un analyseur syntaxique de données. Une option pourrait être de construire votre propre analyseur. Mais cette solution est-elle vraiment judicieuse?
Construire son propre analyseur de parsing ou non?
Pour répondre à cette question, nous allons vous présenter les avantages et les inconvénients de la construction de votre propre analyseur syntaxique. Après cela, vous devriez être en mesure de prendre une décision en connaissance de cause.
Avantages de la construction de son propre analyseur syntaxique
- Vous avez plus de contrôle → Vous avez plus de contrôle et pouvez décider comment mettre à jour ou maintenir votre analyseur de données. En outre, si vous traitez des données très sensibles, vous pouvez préférer ne pas partager vos informations avec des analyseurs de données tiers.
- Personnalisable en fonction de vos besoins → Lorsque vous créez votre propre analyseur, il est spécifiquement adapté à votre entreprise. Cela permet aux équipes internes de répondre aux exigences spécifiques de votre organisation en matière d’analyse syntaxique.
Inconvénients de la construction de son propre analyseur syntaxique
En général, pour construire votre propre analyseur, vous aurez besoin d’une équipe de développeurs capables de comprendre et d’écrire des applications d’analyse. Trouver des développeurs possédant ces compétences peut constituer un véritable défi. Mais ce n’est pas la seule difficulté. Voyons quels sont les autres inconvénients liés à la création de votre propre analyseur syntaxique:
- Coûteux → La création de votre propre analyseur est coûteuse, car elle nécessite beaucoup de temps et de ressources. En outre, vous devrez engager et former toute une équipe interne pour construire votre analyseur personnalisé.
- Entraînement du personnel → Vous devrez former l’ensemble de votre personnel à l’utilisation de la technologie d’analyse syntaxique des données.
- Maintenance → Un analyseur de données nécessite une maintenance régulière, ce qui signifie que vous devrez y consacrer plus de temps et d’argent.
- Infrastructure → La mise en place d’un analyseur de données nécessite beaucoup de planification et des serveurs exclusifs. Cela signifie que vous devrez peut-être construire ou acheter un serveur puissant suffisamment rapide pour analyser les informations.
Pour la plupart des organisations, les inconvénients surpassent les avantages, tout simplement parce qu’il est coûteux et extrêmement difficile de trouver des personnes expérimentées pour construire un analyseur syntaxique. Si c’est le cas, il n’y a pas de raison de désespérer. Nous avons une autre option pour vous. Vous pouvez enrichir votre organisation d’un analyseur de données qui a été construit par des milliers d’heures de travail de développeurs.
Parsing de données avec Doxis
Doxis est l’une des entreprises qui peut être utilisée pour analyser des données à partir de n’importe quel type de document. Pour analyser les données, un logiciel de reconnaissance optique de caractères (OCR) est nécessaire.
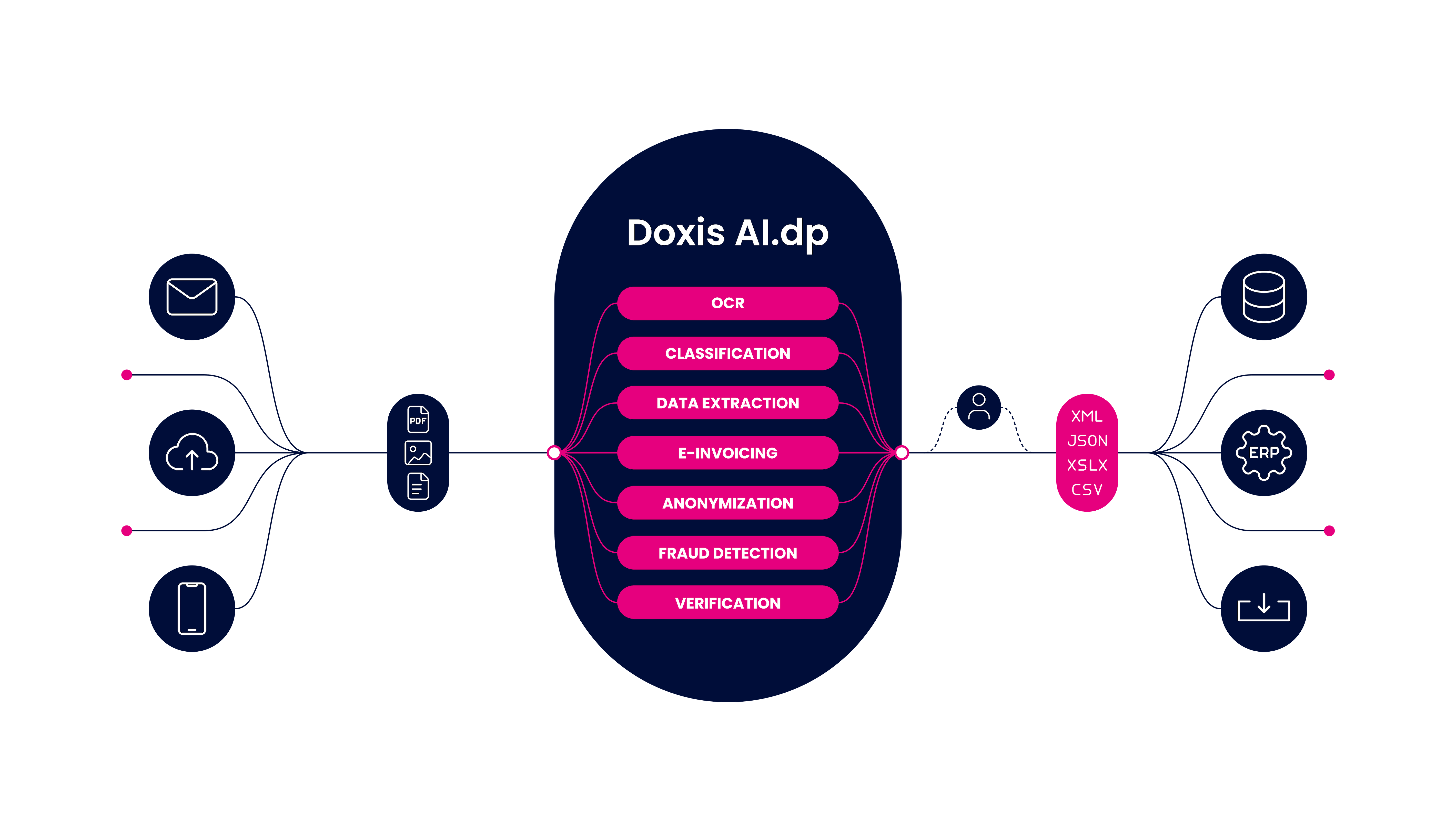
Doxis AI.dp, notre logiciel d’OCR basé sur l’IA, peut être utilisé pour analyser les données de tout type de document que votre organisation doit traiter. Grâce à la technologie OCR, vous pouvez extraire avec précision des informations pertinentes à partir de formats de données non structurés et convertir ces données dans le format souhaité.
En outre, AI.dp peut classer les types de documents, vérifier et anonymiser les données, tout en éliminant la saisie manuelle des données. AI.dp reconnaît déjà un large ensemble de documents dans plus de 100 langues.
Vous souhaitez transformer vos données bloquées dans des formats inutilisables en données prêtes à l’emploi? Nous nous ferons un plaisir de vous montrer comment y parvenir grâce à notre solution. Réservez une démonstration gratuite ci-dessous ou contactez l’un de nos experts.