
Vous vous demandez si vous devez utiliser Tesseract ou non? Tesseract est la solution d’OCR ‘open-source’ préférée de la plupart des organisations car elle est gratuite, bien connue et a de nombreux cas d’utilisation.
Cependant, le marché du traitement de documents est en pleine mutation. Selon l’IDP Survey 2025, 66 % des entreprises remplacent leurs outils de traitement de documents intelligents anciens par des systèmes modernes alimentés par l’IA, et 78 % utilisent déjà l’IA dans leurs flux de travail documentaires.
Dans ce contexte, bien que Tesseract reste populaire, il appartient de plus en plus à la catégorie des « anciens » : puissant pour les tâches de base, mais souvent dépassé en termes de précision, d’automatisation et d’évolutivité.
Dans ce blog, nous allons expliquer ce qu’est Tesseract, comment il fonctionne et si Tesseract est la bonne option pour votre cas d’utilisation.
Points clés
- Tesseract est gratuit, mais exigeant à configurer – Bien qu’il soit open-source et populaire, il nécessite du temps, des compétences en Python et des bibliothèques tierces pour atteindre un niveau de performance optimal.
- L’intégration avec Python permet une grande flexibilité – Grâce à des wrappers comme Pytesseract, Tesseract peut être intégré dans des workflows personnalisés, notamment pour la saisie de données automatisée, l’archivage numérique, ou l’extraction de données de documents clients.
- La qualité dépend fortement du prétraitement d’image – Pour obtenir de bons résultats, Tesseract doit être couplé à des outils comme OpenCV afin d’améliorer les images avant analyse (netteté, contraste, redressement…).
- Il existe des limites importantes – Tesseract ne reconnaît pas l’écriture manuscrite, manque d’interface graphique, et demande un long entraînement pour des cas spécifiques. Pour des projets à grande échelle ou critiques, une solution plus moderne comme Klippa DocHorizon peut s’avérer plus efficace et rapide à déployer.
Qu’est-ce que Tesseract?
Tesseract est un moteur OCR open-source qui extrait le texte imprimé ou écrit des images. Il a été développé à l’origine par Hewlett-Packard, et son développement a ensuite été repris par Google. C’est pourquoi il est maintenant connu sous le nom de “Google Tesseract OCR”.
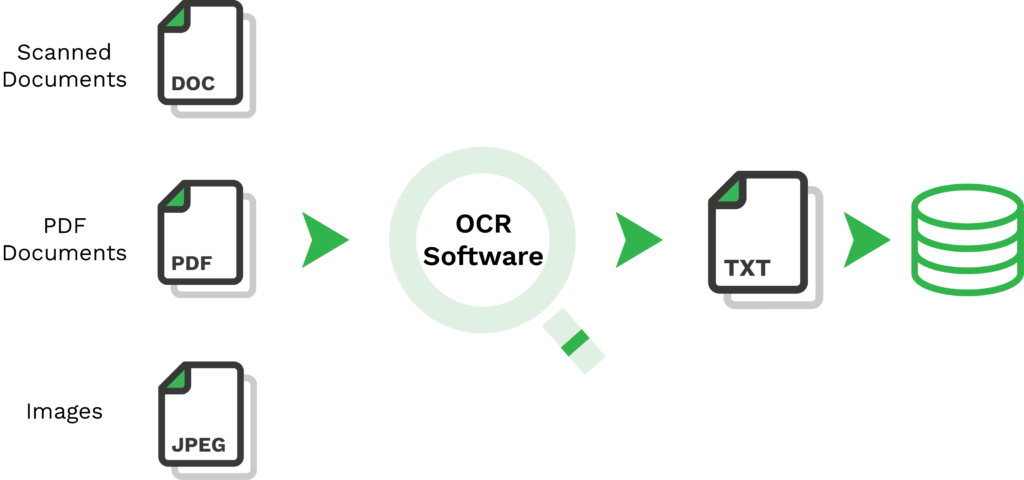
Mais qu’est-ce qu’un OCR ‘open-source’? Cela signifie simplement qu’il est disponible pour que chacun puisse l’utiliser librement, soit directement, soit en utilisant une interface de programmation d’applications (API). Avec l’OCR de Tesseract, les utilisateurs peuvent extraire du texte des images grâce à une reconnaissance efficace des lignes et des caractères du moteur d’OCR.
À l’heure actuelle, Tesseract prend déjà en charge la reconnaissance linguistique pour plus de 100 langues “prêtes à l’emploi”. La version la plus récente de Tesseract (4.0) intègre l’IA par le biais du réseau neuronal LSTM pour mieux détecter et reconnaître les entrées de tailles diverses.
L’une des grandes forces de Tesseract est qu’il est compatible avec de nombreux langages et cadres de programmation grâce à des wrappers tels que Pytesseract, également connu sous le nom de Python-Tesseract. Examinons de plus près cette connexion entre Tesseract OCR et Python.
Logiciel d’OCR Open Source en Python
Pytesseract n’est pas seulement un OCR en Python, un logiciel open-source ou une bibliothèque Python, mais sert également de wrapper pour le moteur OCR Tesseract de Google. Ce qu’il fait est d’envelopper le code Python autour de Tesseract OCR, assurant la compatibilité et la capacité de fonctionner avec différentes structures logicielles.

Notez qu’il existe d’autres bibliothèques et wrappers Python OCR qui peuvent être couplés avec Tesseract, notamment:
- PYOCR – permet plus d’options pour la détection des phrases, des chiffres et des mots
- Textract – permet l’extraction de données PDF pour les fichiers et paquets volumineux
- OpenCV – bibliothèque open-source de fonctions de programmation centrées sur la vision d’ordinateur (CV) en temps réel
- Leptonica – permet des fonctions de traitement d’images et des applications d’analyse d’images avec sa bibliothèque d’imagerie
- Pillow – une autre bibliothèque d’imagerie Python, qui prend en charge l’ouverture, la manipulation et l’enregistrement d’une liste étendue de formats de fichiers d’image
Maintenant que nous avons expliqué ce qu’est Tesseract et quel est son lien avec Python, voyons les étapes du processus d’OCR de Tesseract.
Étapes du processus d’OCR de Tesseract
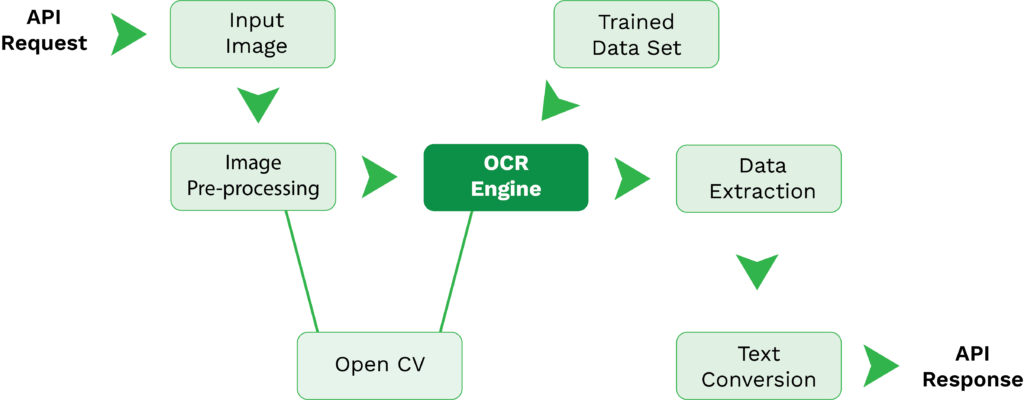
Pour vous aider à comprendre à quoi ressemble normalement le processus d’OCR de Tesseract, nous l’avons décomposé en plusieurs étapes suivantes:
- Demande d’API – L’accès à Tesseract OCR ne peut se faire que par l’intégration d’une API. Une fois que la connexion entre votre solution et Tesseract est établie, vous pouvez envoyer des requêtes API de votre solution au moteur OCR de Tesseract.
- Image d’entrée – Avec une demande API, vous pouvez envoyer votre image d’entrée pour l’extraction de texte.
- Pré-traitement de l’image – Avant l’extraction des données, les fonctions de pré-traitement de l’image du moteur OCR de Tesseract entrent en jeu. Cette étape existe pour s’assurer que la qualité de l’image est aussi élevée que possible pour obtenir des résultats d’extraction de données précis. OpenCV est souvent couplé à Tesseract pour améliorer la qualité de l’image avant l’extraction des données.
- Extraction des données – Avec des ensembles de données entraînés et Leptonica ou OpenCV, le moteur OCR de Tesseract traite l’image d’entrée et extrait les données.
- Conversion du texte – Les données (texte) ayant été extraites de l’image d’entrée, elles peuvent maintenant être converties dans un format souhaité pris en charge par Tesseract, notamment PDF, texte brut, HTML, TSV et XML.
- Réponse API – Une fois que la sortie est prête, votre solution recevra une réponse API avec la sortie finalisée.
Pour mettre en place ce flux OCR, il faudra des connaissances et du temps pour établir toutes les connexions API pertinentes. En outre, vous devrez trouver les composants pertinents, tels que les bibliothèques et les wrappers, et effectuer un codage approfondi. Cela dépend principalement de votre cas d’utilisation et de votre application de l’OCR.
Comme indiqué précédemment, Tesseract est souvent associé à OpenCV pour améliorer la qualité de l’image d’entrée en fonction des normes actuelles. Voyons plus en détail comment cela fonctionne.
Amélioration du traitement des images en combinant OpenCV et Tesseract
Pour comprendre pourquoi OpenCV est souvent combiné avec l’OCR de Tesseract, nous devons expliquer la vision de l’ordinateur. La vision par ordinateur est un sous-domaine de l’intelligence artificielle (IA) qui permet aux ordinateurs et aux logiciels de voir, d’observer et de comprendre des images numériques, des vidéos ou d’autres données visuelles. Mais qu’est-ce que cela a à voir avec OpenCV?
OpenCV est une bibliothèque open-source de fonctions de vision par ordinateur qui peut améliorer l’extraction de données des moteurs OCR tels que Tesseract. Pour ce faire, vous pourriez utiliser la bibliothèque OpenCV pour intégrer les fonctions suivantes dans la solution OCR:
- Détection d’objets – permet à la solution de détecter une grande variété d’objets
- Réseaux neuronaux profonds (DNN) – permet à la solution de classer les images
- Traitement de l’image – permet à la solution de mieux traiter les images d’entrée grâce à diverses techniques telles que la détection des bords, la manipulation des pixels, le redressement, etc.
Sans OpenCV, Tesseract n’est pas aussi sophistiqué que ce que l’on pourrait attendre des solutions d’OCR actuelles, car beaucoup d’entre elles appliquent diverses technologies d’IA.
Maintenant que vous savez que l’OCR Tesseract peut être amélioré avec d’autres bibliothèques de fonctions de programmation telles qu’OpenCV, examinons de plus près l’un des wrappers Tesseract les plus utilisés en Python: PyTesseract.
Comment fonctionne (Py)Tesseract?
Jusqu’à présent, nous savons que Pytesseract est un wrapper pour l’OCR Tesseract de Google en Python avec des fonctionnalités supplémentaires que Tesseract seul n’a pas. Quelles sont donc ces fonctionnalités et comment cela fonctionne-t-il?
Pytesseract peut être utilisé comme un script autonome pour Tesseract ce qui lui permet d’imprimer le texte reconnu au lieu de le convertir dans un fichier. Pytesseract peut lire tous les fichiers images supportés par les bibliothèques d’imagerie telles que Leptonica et Pillow, y compris JPEG, PNG, GIF, BMP, TIFF, et beaucoup d’autres. Il est donc souvent utilisé dans les cas d’utilisation de l’OCR Python de l’image au texte.
Le fonctionnement de Pytesseract est le suivant: il convertit les éléments textuels et graphiques d’une image numérisée en un bitmap. Ce bitmap est simplement une construction de points blancs et noirs. Comme pour toute OCR, l’image passe par une phase de prétraitement pour les ajustements de luminosité et de contraste avant l’extraction et la conversion des données.

Le framework Pytesseract est optimisé pour une meilleure détection de la langue, ce qui profite également à l’OCR Tesseract de Google. En outre, ce cadre est excellent pour détecter les polices de caractères utilisées et l’orientation du texte sur l’image d’entrée. Par exemple, il peut fournir un chiffre de confiance d’orientation pour assurer la détection de l’orientation. Cependant, l’une de ses caractéristiques les plus importantes est qu’il peut vous fournir des informations sur la boîte de contour de l’OCR.
Se familiariser avec les fonctionnalités et le fonctionnement de l’OCR Python de Pytesseract est bien, mais cela ne vous donne aucun détail sur la façon d’utiliser l’OCR Tesseract de Google. C’est ce que nous allons faire maintenant!
Cas d’utilisation de l’OCR en python avec Tesseract
Si vous êtes dans une entreprise qui traite des documents provenant de clients, de fournisseurs, de partenaires ou d’employés, il y a de fortes chances que vous puissiez améliorer votre flux de traitement de documents avec l’OCR de Tesseract. Nous avons énuméré ci-dessous quelques-uns des cas d’utilisation dans lesquels l’OCR de Python peut être appliqué.
- Saisie de données automatisée – Les goulots d’étranglement sont souvent causés par des tâches fastidieuses comme la saisie de données. Avec l’OCR, vous pouvez éliminer la saisie manuelle des données et réduire les coûts jusqu’à 70%.
- Enregistrement numérique des clients – L’OCR peut être très utile pour extraire les informations personnelles des documents d’identité. Avec l’OCR, vous pouvez fournir à vos clients une solution d’accueil à distance sans avoir besoin d’un processus d’accueil à la réception.
- Nettoyage automatisé des reçus pour les campagnes de fidélisation – Que faire si vous avez une grande campagne de fidélisation avec une quantité importante de reçus à vérifier? Vous devez d’abord extraire les données dans votre base de données avant de les valider. C’est à cela que Tesseract peut vous aider.
- Traitement automatisé des factures pour les comptes créditeurs – Les processus des comptes créditeurs passent par de nombreuses étapes et commencent toujours par une saisie manuelle des données. Avec l’OCR, vous pouvez réduire le temps d’exécution et les coûts grâce à l’extraction automatisée des données des factures.
- Archivage numérique – Retrouver un élément d’information dans des archives papier peut prendre beaucoup de temps. L’archivage numérique avec OCR présente de nombreux avantages pour les organisations, notamment des économies de coûts, la conformité au GDPR et un meilleur accès aux données.
- Extraction de données de NIV – L’inscription manuelle des numéros d’identification des véhicules (NIV) sur le papier ou les formulaires n’est pas toujours le moyen le plus efficace de les traiter. L’extraction du NIV avec l’OCR de Tesseract est simple, et peut stimuler vos opérations de manière significative.
Ne vous inquiétez pas si votre cas d’utilisation n’a pas été décrit ici. Tesseract peut généralement améliorer de nombreux flux de travail liés aux documents, comme toute autre solution Python d’OCR. Cependant, il faut garder à l’esprit qu’il ne s’agit pas d’une solution prête à l’emploi.
Cela signifie que pour chacun des cas d’utilisation mentionnés ci-dessus, vous devez coupler plusieurs API et utiliser une variété de wrappers Python et de bibliothèques de fonctions de programmation. En outre, vous devrez former le moteur d’OCR à l’aide d’une quantité importante de données pour prendre en charge votre cas d’utilisation, ce qui nécessite des tonnes de ressources, en temps et en argent.
Entraîner Tesseract pour traiter vos fichiers
Dans les cas où Tesseract ne prend pas en charge vos besoins en matière d’extraction de données, vous devez former vous-même le moteur OCR. En pratique, cela signifie que vous devez disposer de milliers d’exemples d’images ou de documents annotés pour entraîner le moteur OCR de Tesseract. Ces données sont également appelées “données d’entraînement”.
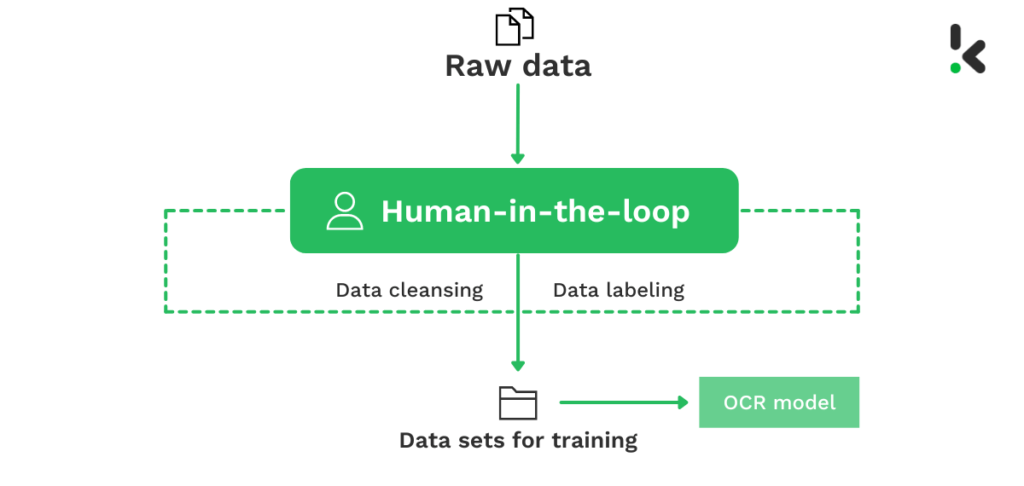
Ce ne sont pas toutes les organisations qui disposent des données de l’apprentissage sur le bout des doigts. Obtenir des données de formation peut coûter à votre organisation une somme d’argent considérable. Et si vous annotez les données vous-même, cela vous coûtera à la fois du temps et de l’argent.
Ce sont souvent les principales raisons pour lesquelles de nombreuses organisations préfèrent opter pour une solution qui offre déjà des options prêtes à l’emploi. Mais il existe d’autres raisons à prendre en compte avant de vous précipiter dans l’utilisation d’une solution OCR open-source comme Tesseract de Google.
Limites du Tesseract
L’OCR de Tesseract peut être très utile dans de nombreuses situations et cas d’utilisation. Cependant, comme toute autre solution open-source, il y a toujours des inconvénients à prendre en compte. Dans cette section, nous allons éclairer ces limitations une par une:
- Tesseract n’est pas aussi précis que des solutions plus avancées intégrant de l’IA
- Tesseract est sujet à des erreurs si la séparation entre le premier plan et l’arrière-plan de l’image n’est pas importante
- Vous avez besoin de beaucoup de ressources et de temps pour développer votre propre solution à l’aide de l’OCR de Tesseract
- Tesseract ne prend pas en charge tous les formats de fichiers par lui-même
- Tesseract ne reconnaît pas l’écriture manuscrite
- La qualité de l’image doit atteindre un certain seuil de points par pouce (DPI) pour qu’elle fonctionne
- Tesseract doit être développé davantage et nécessite l’intégration de l’IA pour pouvoir automatiser certains processus documentaires (par exemple, la vérification, la validation par recoupement, etc.)
- Tesseract n’a pas d’interface utilisateur graphique (GUI), ce qui signifie que vous devez le connecter à votre GUI existante ou en faire développer une
- Le développement supplémentaire vous coûtera du temps et de l’argent
En résumé, si votre cas d’utilisation de l’OCR est simple et que vous savez en interne comment développer des solutions d’OCR à l’aide de Python, alors Tesseract de Google peut être une solution suffisante pour vous.
Toutefois, si vous avez besoin d’une solution d’OCR plus précise, évolutive ou prête à l’emploi, Tesseract n’est pas la meilleure solution pour vous. Bien que son utilisation soit gratuite, les options payantes sont souvent plus faciles et peuvent même être moins chères que l’utilisation de Tesseract. Autres raisons pour lesquelles ce n’est peut-être pas le bon choix pour vous:
- Un temps d’installation long
- La nécessité d’établir des connexions avec les systèmes ERP ou comptables
- Manque de soutien pour votre cas d’utilisation
- Manque de données de formation
- Manque de connaissances en interne sur l’OCR en Python
L’alternative parfaite à Tesseract OCR: Klippa DocHorizon
Klippa DocHorizon est considéré comme la prochaine évolution de la technologie OCR. Avec plus de dizaines de milliers d’heures de développement, la solution a été perfectionnée pour servir des clients dans de multiples industries.
DocHorizon peut non seulement convertir des images en texte par OCR, mieux que Tesseract OCR, mais aussi classer, valider et masquer des données automatiquement en utilisant des technologies d’intelligence artificielle.
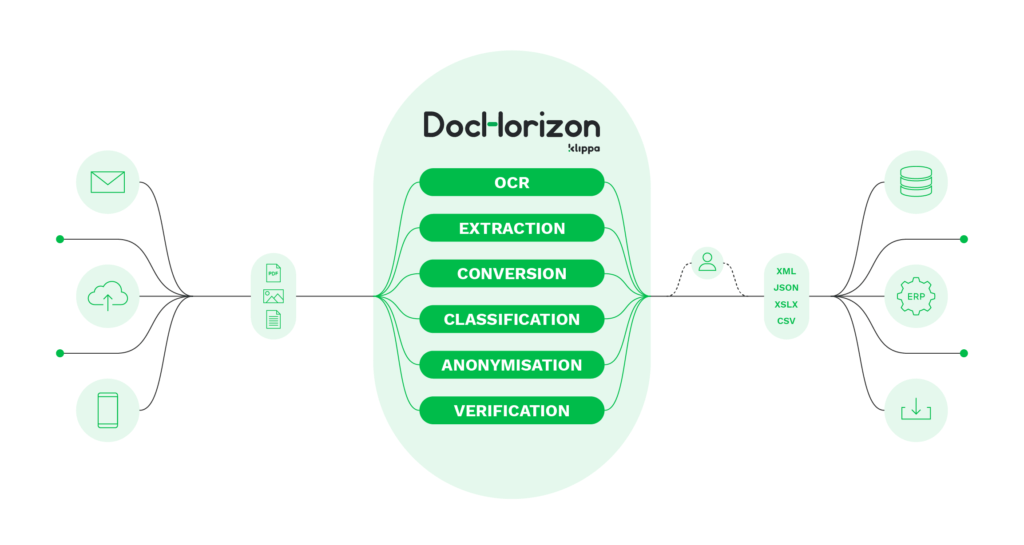
Pourquoi préférer DocHorizon à Tesseract OCR? Les avantages de l’utilisation de Klippa DocHorizon par rapport à Tesseract sont les suivants:
- Évolutivité – DocHorizon n’est pas limité par des modèles ou certains fichiers d’entrée, ce qui permet à votre organisation d’étendre ses opérations d’OCR
- Large éventail de types de documents supportés – Actuellement, il existe des options prêtes à l’emploi pour capturer des données à partir de documents tels que des passeports, des reçus, des factures, des cartes d’identité, des permis de conduire, et bien d’autres dans plusieurs langues
- Équipe d’intégration spécialisée – Permet une intégration rapide et fiable pour que vous puissiez démarrer le plus rapidement possible
- Précision accrue de l’OCR – Grâce aux technologies d’IA, la précision de l’OCR est plus élevée car la solution est en apprentissage constant et n’est pas limitée à des modèles ou à des règles strictes
- Automatisation du flux de documents – DocHorizon peut automatiser tout flux de documents, ce qui vous permet d’éliminer les tâches répétitives telles que l’archivage manuel, la saisie manuelle des données et la validation des données
- Numérisation mobile – Faites passer votre entreprise à un autre niveau en permettant à votre organisation ou à vos clients d’effectuer l’OCR d’images avec des appareils mobiles grâce aux solutions de numérisation mobile de DocHorizon
- Solution personnalisée – Si vous avez besoin d’une solution personnalisée adaptée à votre cas d’utilisation, l’équipe de développement expérimentée de Klippa peut vous aider à la construire
En conclusion, DocHorizon prend en charge beaucoup plus de cas d’utilisation prêts à l’emploi que Tesseract OCR de Google. Si votre organisation a un cas d’utilisation plus complexe ou si vous souhaitez mettre en œuvre une solution prête à l’emploi, DocHorizon est la meilleure alternative à Tesseract pour vous.
Programmez une démonstration à l’aide du formulaire ci-dessous pour voir comment notre solution fonctionne. Si vous avez des questions brûlantes auxquelles nous n’avons pas encore répondu, n’hésitez pas à contacter nos experts.
FAQ
Tesseract est un moteur OCR (Reconnaissance Optique de Caractères) open-source développé par Hewlett-Packard et désormais maintenu par Google. Il permet d’extraire du texte à partir d’images ou de documents scannés dans plus de 100 langues. Il est surtout utilisé par les développeurs dans des environnements Python.
Tesseract est une boîte à outils technique : il faut l’installer, le configurer, et l’entraîner manuellement pour des cas spécifiques. En revanche, Klippa DocHorizon est une solution OCR tout-en-un, prête à l’emploi, basée sur l’intelligence artificielle, qui permet non seulement l’extraction de texte, mais aussi la classification, la validation et l’automatisation des flux de documents.
Oui, Tesseract utilise un réseau neuronal LSTM depuis sa version 4.0, ce qui améliore ses performances par rapport aux versions précédentes. Toutefois, des solutions comme Klippa DocHorizon vont plus loin, en intégrant des modèles IA de dernière génération entraînés sur des millions de documents, pour une reconnaissance plus précise et rapide.
Si vous avez une équipe technique prête à développer une solution sur mesure, Tesseract peut convenir pour des projets simples. Mais si vous cherchez une solution fiable, rapide à intégrer et adaptée à des cas d’usage métiers (RH, finance, comptabilité, juridique, etc.), Klippa DocHorizon est l’alternative idéale à Tesseract OCR.