L’extraction d’informations à partir de documents est une tâche quotidienne pour la plupart des organisations. Pour améliorer l’efficacité de cette tâche, les entreprises se sont tournées vers l’automatisation. L’extraction des données se fait désormais à l’aide de technologies modernes, telles que l’IA, la vision par ordinateur ou le traitement du langage naturel (NLP). Grâce à l’automatisation, les entreprises réduisent leur temps de traitement des documents et augmentent la précision des données extraites.
Pour améliorer la rapidité et l’efficacité du flux de travail, les entreprises utilisent souvent la reconnaissance des entités nommées (NER) pour automatiser les processus d’extraction d’informations. La NER est l’une des techniques de traitement du langage naturel et elle peut être très bénéfique pour les organisations qui cherchent à maximiser leurs capacités d’automatisation.
Si le terme de reconnaissance des entités nommées ne vous est pas familier ou si vous ne savez pas comment le mettre en œuvre, ne vous inquiétez pas. Dans ce blog, nous verrons ce qu’est la reconnaissance des entités nommées et comment vous pouvez construire ou entraîner un modèle NER. Ensuite, nous examinerons quelques-unes des possibilités d’implémentation de la NER à l’aide de code, à savoir nltk et spaCy.
Commençons.
Qu’est-ce que la reconnaissance des entités nommées (NER) ?
La reconnaissance des entités nommées est une technique basée sur le NLP, utilisée pour extraire, identifier et catégoriser des informations dans des documents textuels. Elle détecte les entités (c’est-à-dire les parties du discours) et les classe dans une catégorie prédéterminée, telle que le nom ou le code du pays.
Les catégories NER peuvent être génériques, indiquant par exemple des mots qui signifient une organisation, une personne ou une période. Toutefois, elles peuvent également être personnalisées en fonction d’un cas d’utilisation spécifique. Pour vous donner un exemple, le modèle NER peut être construit pour reconnaître des catégories telles que « nom du patient » et « date de naissance » sur les documents de santé ou « nom du commerçant » et « date d’achat » sur les factures. Les possibilités sont infinies.
Pour obtenir les résultats les meilleurs et les plus précis, la reconnaissance des entités nommées nécessite une bonne connaissance des mathématiques, de Machine Learning et du traitement des images. Mais la liste ne s’arrête pas là. La reconnaissance des entités nommées peut être basée sur de multiples méthodes, c’est pourquoi nous allons approfondir ce sujet et découvrir les différentes approches de la reconnaissance des entités nommées.
Méthodes de reconnaissance des entités nommées
Comme indiqué précédemment, la reconnaissance des entités nommées peut être basée sur plusieurs méthodes. La différence entre ces méthodes réside dans la manière dont le modèle a été entraîné pour identifier et extraire avec précision les champs de données.
- Méthode basée sur le dictionnaire : Dans cette méthode, un dictionnaire contenant un vocabulaire étendu est utilisé pour former le modèle NER. Un algorithme de correspondance de chaînes de base est utilisé pour vérifier si une entité présente dans le texte donné correspond à un élément du vocabulaire.
- Méthode basée sur des règles : Selon cette méthode, un ensemble prédéterminé de règles est utilisé pour l’extraction d’informations. Ces règles peuvent être basées sur le modèle, en utilisant le modèle morphologique des mots, ou basées sur le contexte, en utilisant le contexte du mot donné dans le document.
- Méthode basée sur Deep Learning : Cette approche est basée sur les statistiques et implique deux étapes pour réaliser le NER. Tout d’abord, les fichiers utilisés pour l’entraînement du modèle sont soumis à un processus d’annotation des données. Ce n’est qu’après cette procédure que le modèle de NER peut commencer à s’entraîner sur les données annotées. La deuxième étape permet au modèle formé d’annoter lui-même les documents bruts.
- Méthode basée sur Deep Learning : Enfin, la méthode basée sur Deep Learning est la plus précise. Elle est capable de comprendre les relations sémantiques et syntaxiques entre les mots d’un texte donné, mais aussi d’analyser les mots spécifiques à un sujet.
La reconnaissance des entités nommées semble être un atout majeur pour extraire des informations avec précision. Mais comment fonctionne-t-elle réellement ? Comprendre le processus qui sous-tend ce modèle permet aux entreprises d’avoir une meilleure idée de ce qu’implique la reconnaissance des entités nommées. Découvrons la procédure de construction et d’entraînement du modèle de reconnaissance des entités nommées.
Comment construire et former un modèle NER
Il est temps d’apprendre à construire et à entraîner un modèle NER à partir de zéro. L’une des approches les plus courantes pour construire un modèle NER consiste à utiliser un modèle de langage, appelé Bidirectional Encoder Representations from Transformers, également connu sous le nom de BERT.
Un modèle BERT est un modèle linguistique pré-entraîné qui peut être affiné et mis à jour. Cela permet au modèle pré-entraîné de mieux comprendre les modèles de texte et d’analyser le contexte et le sens. Il utilise la technique NER à la base, mais offre la possibilité de s’entraîner et de se perfectionner, ce qui améliore sa précision de fonctionnement.
Examinons les cinq étapes nécessaires pour construire et entraîner le modèle de reconnaissance des entités nommées, en utilisant le modèle de langue BERT :
- Acquisition de données
- Préparation des données pour la reconnaissance des entités nommées
- Initialisation des hyperparamètres pour le modèle NER
- Entraînement et prédiction du modèle BERT
- Estimation des performances du modèle de reconnaissance des entités nommées
Acquisition de données
La première étape de toute procédure impliquant des modèles basés sur Deep Learning, tels que l’ORET, consiste à alimenter le modèle en données. De cette manière, l’algorithme est capable de traiter les informations données et de les assimiler. Pour se familiariser avec les entités (c’est-à-dire les noms, les lieux, les organisations, les codes de pays), le modèle doit disposer de connaissances préalables. Ce n’est qu’ensuite qu’il peut reconnaître et différencier les entités dans un contexte.
Bien qu’un modèle BERT soit particulièrement entraîné sur des phrases contenant l’entité d’intérêt, par exemple « personne », il peut également être entraîné à reconnaître des mots à l’aide de sous-mots. Supposons que nous ayons l’entité « personne ». Un sous-mot pour cette entité serait le nom d’une personne. Avec un entraînement suffisant, le modèle peut reconnaître que chaque mot qui est le nom d’une personne correspond à l’entité « personne ». C’est pourquoi il est nécessaire de disposer d’un grand nombre de données.
Préparation des entrées pour le modèle de reconnaissance des entités nommées
Avant de passer à la deuxième étape, il est important de rappeler que le modèle NER utilise un schéma de marquage spécifique, contrairement à d’autres modèles de traitement du langage naturel. Le schéma d’étiquetage préféré est le format IOB, en raison de sa facilité d’utilisation. Il est couramment utilisé pour étiqueter les tokens (c’est-à-dire les entités, les mots) dans une tâche de découpage pour le modèle NER.
Au cas où vous vous poseriez la question, le découpage est un processus de TAL utilisé pour identifier les parties du discours dans une phrase. Les parties du discours sont les noms, les verbes, les adjectifs, etc. Une tâche de découpage est donc chargée d’identifier ces entités et de les étiqueter en conséquence.
Le format IOB signifie « Inside, Outside, Beginning » (intérieur, extérieur, début) et se présente comme suit:
- Le préfixe « I » précédant une balise indique que le jeton se trouve à l’intérieur d’un bloc.
- Le préfixe « O » indique qu’un élément n’appartient à aucun bloc.
- Le préfixe « B » devant une balise indique que la balise concernée est le début d’un bloc et qu’elle suit immédiatement un autre bloc sans balise « O » entre eux. Toutefois, si un bloc suit un préfixe « O », le premier élément du bloc prend un préfixe « I », au lieu du « B ».

Une alternative au schéma de balisage IOB consiste à utiliser des frameworks existants, tels que TensorFlow. Dans ce cas, l’utilisation de classes de pré-processeur est nécessaire pour effectuer le balisage.
Initialisation des hyperparamètres pour le modèle NER
La troisième étape du processus consiste à charger le modèle linguistique BERT dans le programme et à initialiser les hyperparamètres. Ces hyperparamètres représentent une référence pour le modèle BERT, de sorte que la formation peut être évaluée avec précision.
Pour trouver les bons paramètres, le modèle doit être affiné en fonction de ses performances sur les données qui lui ont été fournies. Les données annotées sont chargées dans le programme afin de servir de tenseurs pour l’entraînement du modèle sur un réseau neuronal profond. Un réseau neuronal profond, ou simplement DNN, est un sous-ensemble de Machine Learning et de Deep Learning, qui traite les données de manière complexe en recourant à la modélisation mathématique.
Pour améliorer la précision de la prédiction des entités, ces hyperparamètres jouent un rôle essentiel dans le modèle.
Formation et prédictions du modèle BERT
Après avoir défini les hyperparamètres, il est temps d’entraîner le modèle BERT. La formation du modèle BERT comprend deux phases. Tout d’abord, l’établissement des directives de formation, suivi de la formation proprement dite du modèle.
- La définition des directives de formation implique l’écriture d’une boucle basée sur le nombre d’époques de Machine Learning. Une époque est le nombre de fois que l’algorithme d’apprentissage travaillera sur l’ensemble des données d’apprentissage. Dans cette phase, il est également important de vérifier les unités de traitement graphique, ou GPU. Ces unités de traitement graphique accélèrent les processus de calcul pour Deep Learning, optimisant ainsi le modèle pour une formation plus rapide.
- La phase suivante est l’entraînement proprement dit du modèle. Nous devons maintenant activer les paramètres qui ont été définis précédemment et initialiser la fonction de perte et la fonction d’optimisation. Ces fonctions permettent d’améliorer les performances du modèle, en augmentant la précision des résultats.
La fonction de perte mesure la différence entre la sortie prédite et la sortie réelle, tandis que l’optimiseur ajuste les paramètres du modèle pour minimiser la fonction de perte.
L’objectif principal est de former le modèle de manière à minimiser les erreurs et à augmenter la précision des taux de prédiction.
Estimation des performances du modèle de reconnaissance des entités nommées
Enfin, nous devons estimer la performance du modèle. Cette estimation peut se faire de différentes manières, mais les plus courantes sont l’utilisation d’un score F1 et d’un score de match détendu.
- Score F1 : Le score F1 est une mesure d’évaluation en ML qui combine les scores de précision et de rappel. Il indique combien de fois un modèle a fait une prédiction correcte sur l’ensemble de la base de données. Cette mesure n’est précise que si chaque classe de l’ensemble de données comporte le même nombre d’échantillons.
- Score de correspondance détendue : Avec cette mesure, la performance est calculée sur la base du nombre d’entités que le modèle a identifiées comme étant le bon type d’entité. Examinons l’exemple suivant :
Supposons qu’il y ait 3 entités « personne » et 2 entités « lieu » dans un texte donné. Si le modèle identifie 4 entités « personne » et 1 entité « lieu » à la place, la performance est de 75 % sur 100 %. La métrique de score de correspondance détendue reconnaît tout de même le modèle comme réussi. Comment cela se fait-il ? Bien que l’identification exacte n’ait pas été possible, le modèle a tout de même reconnu les 3 « entités personnes », ce qui est considéré comme un résultat positif.
Nous venons d’apprendre à construire et à entraîner un modèle de reconnaissance des entités nommées à partir de zéro, en utilisant le modèle de langue BERT. La véritable astuce réside dans l’implémentation du modèle de reconnaissance des entités nommées. Découvrons comment mettre en œuvre ce modèle basé sur le NLP à l’aide du code.
Mise en œuvre de la reconnaissance des entités nommées
L’utilisation du code est le choix préféré lorsqu’il s’agit de mettre en œuvre la NER. Bien qu’il existe de nombreux langages de programmation utilisés pour cette action, nous nous concentrerons sur deux langages spécifiques, à savoir spaCy et nltk. Tous deux sont basés sur Python et permettent d’effectuer des tâches NLP avancées.
Reconnaissance d’entités nommées à l’aide de spaCy
SpaCy est une bibliothèque NLP open-source pour les tâches avancées de traitement du langage naturel en Python. Elle est utilisée pour diverses tâches et fait appel à des méthodes intégrées pour la reconnaissance des entités nommées.
Un modèle SpaCy fonctionne bien sur tous les types de données textuelles, mais il peut être affiné pour des catégories spécifiques. Il existe également plusieurs modèles pré-entraînés dans SpaCy qui peuvent être utilisés pour effectuer des tâches telles que la reconnaissance d’entités nommées ou l’extraction d’informations sur des données spécifiques.
Il est bon de garder à l’esprit que pour mettre en œuvre la NER avec spaCy, il est nécessaire d’avoir les dernières versions de Python 3, Pip et bien sûr, spaCy. De plus, il est également recommandé de télécharger les modèles pré-entraînés de spaCy core pour les utiliser directement dans les programmes. Commençons !
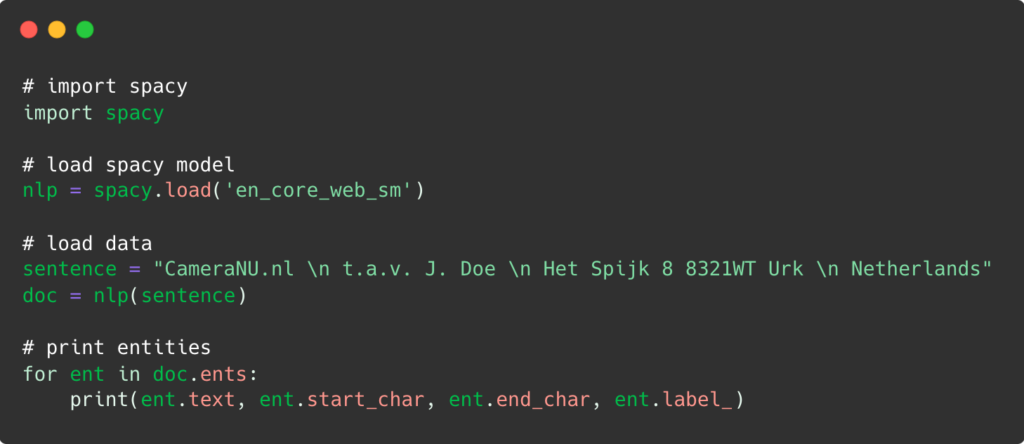
Tout d’abord, nous utilisons un terminal ou une invite de commande et nous tapons la commande suivante:

Ensuite, nous ajoutons le code correspondant:
Une fois que la reconnaissance des entités nommées a traité les informations données, c’est-à-dire qu’elle a lu le texte, identifié les entités et les a classées, nous obtenons le résultat final :

C’est aussi simple que possible. Bien entendu, la précision des données extraites et catégorisées dépend largement de la taille du texte. Dans ce cas, nous pouvons utiliser différents modèles, en fonction de la taille du texte :
- En_core_web_sm – pour les textes de petite taille
- En_core_web_md – pour les textes de taille moyenne
- En_core_web_lg – pour les textes de grande taille
Nous avons vu comment la reconnaissance d’entités nommées peut être mise en œuvre avec spaCy. Mais qu’en est-il de l’implémentation de la NER en utilisant une autre plateforme basée sur Python ? Voyons comment l’implémentation de la reconnaissance des entités nommées se présente avec nltk.
Reconnaissance d’entités nommées à l’aide de nltk
Nltk est également une bibliothèque basée sur Python qui effectue des tâches de traitement du langage naturel. Ces tâches vont du traitement de données textuelles à la modélisation de données en passant par l’étiquetage de parties du discours. En termes de configurations supplémentaires, elle est simple et peut être largement utilisée sur tous les systèmes d’exploitation.
Pour pouvoir utiliser nltk afin d’implémenter la reconnaissance d’entités nommées, il est nécessaire d’installer les paquets stables Python 3, Pip et nltk. L’implémentation de la reconnaissance des entités nommées à l’aide de nltk se fait en trois étapes.
Tout d’abord, il faut importer nltk et télécharger les paquets nécessaires :

Après avoir mis en place tous les paquets nécessaires, il est temps de charger les données. Dans le cas présent, nous avons choisi une phrase que l’on trouve sur une facture.

Enfin, la plate-forme identifie les entités dans le texte donné, trouve les parties du discours pertinentes et délimite les mots dans le document. Le traitement des informations génère le résultat suivant :

Nous pouvons voir que l’utilisation de nltk pour mettre en œuvre la reconnaissance des entités nommées est également un processus simple, tout comme spaCy. Cependant, le fait de savoir comment fonctionne la reconnaissance des entités nommées n’apporte aucune valeur ajoutée aux organisations si elles n’en reconnaissent pas les avantages. Dans la section suivante, nous avons mis en évidence certains des cas d’utilisation les plus importants pour lesquels la reconnaissance des entités nommées peut être d’une grande aide pour les organisations.
Cas d’utilisation des NER
Pour les entreprises qui souhaitent améliorer leurs processus opérationnels, la reconnaissance des entités nommées peut être un atout majeur. Elle peut aider les organisations à effectuer des tâches telles que l’analyse des données, permettant ainsi une automatisation précise de la saisie des données. Ce ne sont là que quelques exemples des avantages de la RNE pour les entreprises :
- Soutien à la clientèle : Les entreprises sont en mesure d’améliorer le taux de satisfaction des clients et de réduire le temps de réponse grâce au NER. Le modèle différencie les plaintes, les questions ou les demandes des utilisateurs reçues par l’intermédiaire des chatbots, en identifiant et en catégorisant les mots-clés utilisés par les clients.
- Catégorisation du contenu : Le contenu est facilement classé dans différentes catégories grâce à la reconnaissance des entités nommées. L’algorithme lit le document et peut instantanément différencier un blog d’un courriel ou d’une entrée de journal. Ce modèle est utilisé pour l’archivage des bibliothèques numériques, la recommandation de films sur les services de streaming ou les détaillants en ligne.
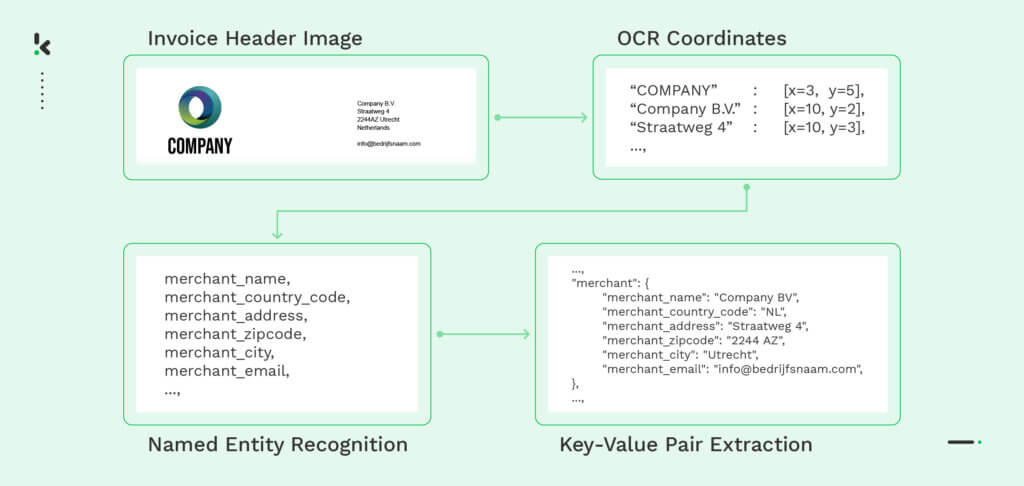
- Classification des documents : La reconnaissance des entités nommées est formée pour différencier plusieurs types de documents, tels que les factures, les reçus ou les passeports. En identifiant simplement des numéros spécifiques ou des champs de données uniques, la reconnaissance d’entités nommées permet de classer les documents dans différentes catégories.
- Analyse de fichiers : Au lieu d’extraire manuellement les données de documents non structurés, les analyseurs de fichiers alimentés par NER peuvent lire le fichier et en extraire les informations les plus importantes. En outre, ils sont capables de transformer les données en un format utilisable pour un traitement ultérieur.
Limites de la construction d’un modèle NER
Construire ou entraîner un modèle de reconnaissance d’entités nommées à partir de zéro n’est pas impossible, comme nous venons de l’apprendre. Cependant, il peut s’agir d’un processus de longue haleine qui s’accompagne de nombreuses limitations :
- C’est coûteux : créer un code à partir de zéro peut être un processus coûteux, que ce soit pour créer le code en interne ou pour l’externaliser. Néanmoins, les ressources financières doivent être consacrées à des experts en informatique ou à l’externalisation du code.
- Cela prend beaucoup de temps : il faut beaucoup de temps pour se former, sans parler de construire un modèle de NER dès le début. Ce processus peut représenter un inconvénient potentiel pour la plupart des entreprises, en particulier les PME.
- Peut être vulnérable aux fuites de données : choisir de construire et de former un modèle NER à partir de zéro peut conduire à des violations de données. Si le modèle n’est pas construit en conséquence, l’algorithme peut devenir vulnérable aux escrocs et aux fuites de données.
- Manque de données de formation : La collecte de suffisamment de données de formation pour alimenter le modèle NER n’est pas une tâche facile. Les entreprises finissent par devoir chercher une alternative, qui consiste généralement à investir de grosses sommes d’argent dans la création de données synthétiques.
Plutôt que d’avoir à gérer une procédure complexe et étendue de construction d’un modèle NER à partir de zéro, les entreprises peuvent choisir une solution prête à l’emploi, à savoir un logiciel de OCR.
Bien qu’il existe de nombreux exemples de logiciels OCR performants, seuls quelques-uns sont en mesure d’effectuer les tâches nécessaires qui peuvent remplacer la technologie de reconnaissance des entités nommées. Klippa DocHorizon, par exemple, est capable de capturer, d’extraire et de vérifier des données, ce qui élimine la nécessité de créer un tout nouveau code.
Alternative de Klippa au modèle de reconnaissance des entités nommées
Klippa DocHorizon est une solution de traitement de documents intelligente qui utilise l’IA pour automatiser les flux de travail liés aux documents. Grâce à la technologie OCR, les entreprises peuvent numériser des documents mobiles, analyser des fichiers, vérifier des documents, masquer des données et bien plus encore.
Klippa DocHorizon permet aux organisations de :
- Traiter les documents financiers, juridiques, d’identité et bien d’autres encore
- Extraction de données avec une précision allant jusqu’à 99 %
- Minimiser les erreurs de saisie des données
- Prévenir la fraude documentaire en vérifiant l’authenticité des documents
- Respecter les réglementations en matière de confidentialité des données, car les données traitées ne sont pas stockées sur les serveurs de Klippa
Au lieu de vous aventurer dans un processus coûteux en temps et en argent, pensez à choisir une solution de traitement intelligent des documents tout-en-un.
Réservez une démonstration gratuite ci-dessous ou contactez-nous si vous avez besoin d’aide pour votre cas d’utilisation NER !