OCR MRZ
Améliorez l’efficacité du traitement des documents d’identité avec l’OCR MRZ. Détectez, extrayez et scannez les zones MRZ automatiquement et en toute sécurité avec le logiciel de reconnaissance de texte (OCR) Klippa.
Plus de 1000 marques dans le monde nous font confiance
Produit
Automatisez la numérisation et le traitement MRZ avec l’OCR Klippa
Nous œuvrons pour automatiser le traitement manuel des données. Y compris le traitement des MRZ. Aidé du SDK Klippa Scanner OCR, le logiciel OCR MRZ reconnaît et extrait les données des documents d’identité avec précision et rapidité. Grâce à un processus automatisé, traitez de plus gros volume de documents, prévenez la fraude et observez votre taux d’erreur décroître drastiquement.
Moins d’erreurs lors de la saisie
Prévention des erreurs de saisie manuelle grâce à notre solution MRZ d’extraction de données de haute qualité.
Plus rapide, moins de coûts
Moins de frais engagés et plus de rapidité grâce au traitement automatique des codes MRZ avec Klippa.
Détection automatique des fraudes
Le logiciel reconnaît automatiquement les erreurs, les fraudes et les doublons.
Numérisation et extraction de données automatisées avec l’OCR MRZ
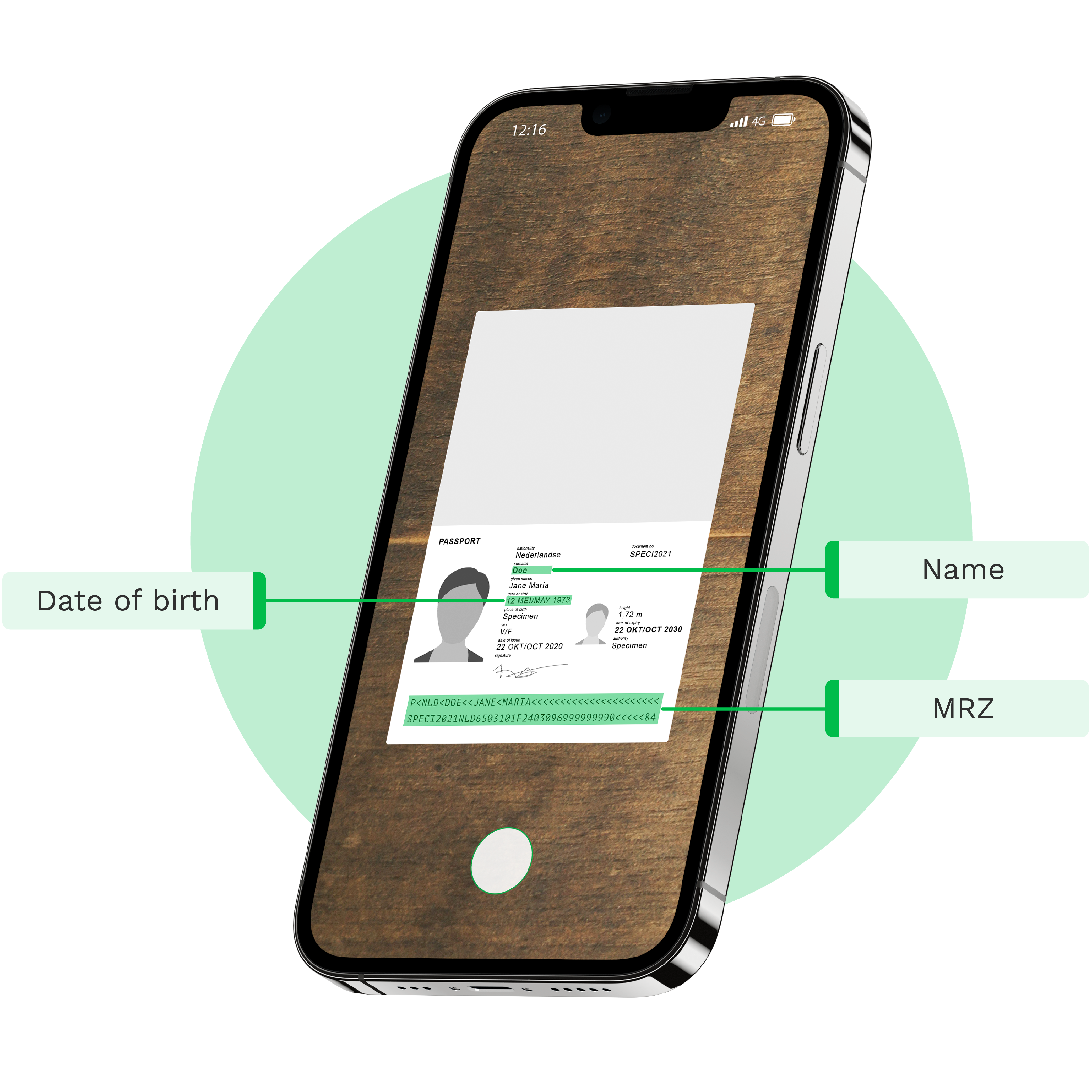
Numérisez les données des zones de lecture automatique (MRZ) avec notre solution OCR sécurisée, précise et rapide. Généralement, les MRZ sont présentes sur les documents d’identité : passeport, carte d’identité et permis de conduire. Pour imager notre explication, nous avons illustré les trois étapes de fonctionnement de notre moteur OCR pour MRZ. Ainsi, vous pourrez mieux visualiser comment l’OCR MRZ extrait automatiquement les zones de lecture automatique des documents.
Étape 1 : numérisation d’une image contenant un MRZ vers le logiciel OCR
Commencer par soumettre l’OCR MRZ un document présentant une zone de lecture automatique. Le format peut être un PDF, une photo tant qu’il contient une MRZ. Téléchargez le document numérisé sur le site internet ou l’application de Klippa. Cette image sera automatiquement analysée et optimisée par l’OCR pour améliorer et simplifier le traitement ultérieur.
Étape 2 : Format TXT en utilisant l’OCR MRZ
Une fois que le logiciel OCR pour les MRZ a scanné le document, ce dernier est converti en fichier TXT. Toutes les informations sont extraites, la MRZ comprise.
Étape 3 : Résultat JSON de l’API
Dans la troisième et dernière étape, le logiciel convertit le fichier TXT au format JSON structuré. Le deep learning et l’analyseur de MRZ entrent en jeu. Ce format JSON est utilisé en sortie de l’API. Dès lors, les données MRZ, à présent structurées, sont disponibles à être intégrées et utilisées dans votre base de données. L’OCR MRZ étant totalement customisable, vous pouvez décider d’extraire d’autres champs : signatures, photographies etc.
Quels sont les champs qui peuvent être extraits ?
Une zone MRZ contient le nom, le numéro du document, la nationalité, la date de naissance, le sexe et la date d’expiration du document d’identité. Il existe parfois des informations supplémentaires facultatives. Voici la liste des champs extractibles du document utilisant l’OCR MRZ. Évidemment, vous pouvez décider d’en extraire d’autres en option, telles que la signature ou la photographie.
Nous prenons au sérieux la confidentialité et la sécurité de vos données
“Il est extrêmement agréable de collaborer avec une entreprise aussi ambitieuse que la nôtre. La volonté et la rapidité avec lesquelles Klippa a mis en œuvre des modifications spécifiques pour nous sont impressionnantes.”
C’est parti !
Réservez une démonstration gratuite et nos experts vous montreront comment automatiser votre flux de documents avec la plateforme DocHorizon.
Foire Aux Questions
Combien coûte l’OCR MRZ ?Qu’est-ce qu’un code MRZ ?Quels types de MRZ existe-t-il ?L’OCR MRZ Klippa peut-il traiter toutes les MRZ ?Quels sont les cas d’utilisation de l’OCR MRZ ?Comment Klippa vérifie-t-il la validité de la MRZ ?Le traitement des MRZ par Klippa est-il conforme à la RGPD ?Existe-t-il une documentation pour l’API ?
La tarification de l’OCR pour les zones de lecture automatique dépend du volume de documents que vous souhaitez traiter mensuellement. Vous pouvez décider d’utiliser des licences à l’utilisation ou des contrats mensuels. Contactez nos spécialistes-produits qui établiront un devis sur mesure.
Une MRZ est une zone codée utilisée sur les documents d’identité tels que les passeports, les cartes d’identité et les permis de conduire. MRZ est l’abréviation de machine readable zone (zone lisible par machine). Il s’agit d’une norme internationale (OACI 9303) établie par les gouvernements, les bureaux de douane et les compagnies aériennes.
C’est une manière sécurisée de compacter les informations des documents d’identité. Les informations codées sont imbriquées dans une suite de caractères pour être lues ultérieurement par un système informatique ou un smartphone via la caméra. Pratiquement tous les documents d’identité français sont munis d’une MRZ, elles sont toutes lisibles et prises en charge par l’OCR MRZ.
Une MRZ consiste en deux ou trois chaînes de caractères, des numéros de somme de contrôle et des séparateurs au recto des passeports ou au verso des cartes d’identité. Pour la chaîne de caractères, une police spéciale appelée OCR-B est utilisée. Cette police est spécifiquement développée pour faciliter la lecture par les ordinateurs et éviter autant que possible les erreurs de lecture. Les numéros de somme de contrôle sont utilisés pour valider les données extraites qui se trouvent dans la MRZ et constituent une mesure de sécurité contre la fraude.
L’OCR MRZ de Klippa fonctionne sur les trois types de MRZ. Il existe trois types de MRZ numérotés MRZ 1, MRZ 2, MRZ 3. Les passeports sont généralement dotés du type 3 et les cartes d’identité du type 1.
– La MRZ 1 s’étend sur trois lignes et chaque ligne comporte 30 caractères. Seuls les caractères A-Z et 0-9 sont inclus, à côté du séparateur. Le format de type 2 n’est pas couramment utilisé, mais s’étend sur deux lignes de 36 caractères.
– Le type 2 ne comprend que des caractères A-Z et 0-9 à côté du séparateur.
– Le MRZ 3 se compose de deux lignes de 44 caractères chacune et comprend le nom, le numéro de passeport, la nationalité, les données de naissance, le sexe et la date d’expiration.
Des données supplémentaires peuvent parfois être ajoutées. Seuls les caractères A-Z et 0-9 sont inclus dans le MRZ et le séparateur.
Saviez-vous qu’a part les codes MRZ, Klippa OCR peut scanner d’autres types de documents d’identité, tels que les cartes d’étudiant, les permis de conduire, etc. Contactez-nous pour plus d’informations.
Oui, Klippa extrait et valide les trois types de chaînes MRZ sur les passeports, les cartes d’identité et autres documents d’identité.
Tous les cas d’utilisation impliquant le traitement d’un grand volume de documents peuvent bénéficier de l’OCR MRZ. Particulièrement l’extraction des champs tels que le nom, la date de naissance, la nationalité, le numéro du document, la durée de validité et plus encore. Généralement, il s’agit de cas liés à la validation d’identité, à l’accueil des clients ou au KYC (processus de connaissance client).
Les chaînes MRZ sont disponibles en trois structures : Type 1, Type 2 et Type 3. Klippa n’accepte que les MRZ dont la structure, la police et la longueur sont correctes pour garantir la validité.
Outre cela, nous validons le contenu de la MRZ en vérifiant qu’elle est composée uniquement de caractères alphabétiques et numériques ainsi que de séparateurs. Les chaînes MRZ contiennent des sommes de contrôle pour valider les données extraites. L’OCR MRZ de Klippa utilise ces sommes de contrôle pour s’assurer que les MRZ sont valides et exactes.
Tous les services que nous proposons sont entièrement conformes à la réglementation RGPD, de même que l’OCR MRZ. Pour le traitement, nous utilisons uniquement des serveurs certifiés ISO au sein de l’UE et un accord de traitement des données est en place. Nous ne stockons ni vos données ou ni celles de vos clients.
Chez Klippa, nous comprenons la valeur d’une API bien documentée. La documentation sur l’OCR MRZ est créée à l’aide de SWAGGER et peut être trouvée via ce lien.